What is the Voynich Manuscript about?
This is the Voynich Manuscript:



It consists of a little over two hundred pages of vellum, covered in an unknown script. Most pages are richly illustrated with non-existent plants, astronomical diagrams and little bathing women. After at least a hundred years of research, the current state of knowledge of the VMs can best be summed up as follows: we don’t know. We don’t what it is and we don’t know what it says. We know it was probably written in the 15th century, and that it’s probably from Italy, but that’s about it. It could be a coded text, it could be a dead or invented language. It could well be a hoax: somebody trying to make some money from an old stock of vellum by filling with enticing scribbles and trying to flog it to some gullible academic.
Given that we know so little, it seems a little presumptuous to ask what it’s about. Surely we would need to translate the thing first. Well, perhaps not.
Level statistics
In Level statistics of words: finding keywords in literary texts and symbolic sequences (abstract, PDF), the authors provide an interesting statistical approach to unsupervised analysis of text that might hold a lot of promise for computational attacks on the VMs.
The approach works as follows. Imagine a book, where every occurrence of a particular words has been highlighted. Consider the distribution of the highlights across the pages. If the word is a common word, like “it” or “the” we will see frequent highlights,in roughly equal numbers on each page. For other words, the number of highlights per page will decrease, but the expected number per page will remain the same. What we are interested in here, is the words for which one page contains a mass of highlights, and two pages on, there are no highlights at all. These are, so goes the theory, the words with high aboutness. They are the words that the text—or at least the section with many highlightsh—is about.
Think of the book as a line, indicating the continuous string of words, where we mark each occurrence of the word of interest with a colored dot. If the words are spread out randomly, we will see the occurrences of the words spread out relatively evenly along the line. For words with high aboutness, we will see the words clustering together, as if they’re particles, attracting each other. Here is an illustration from the paper:
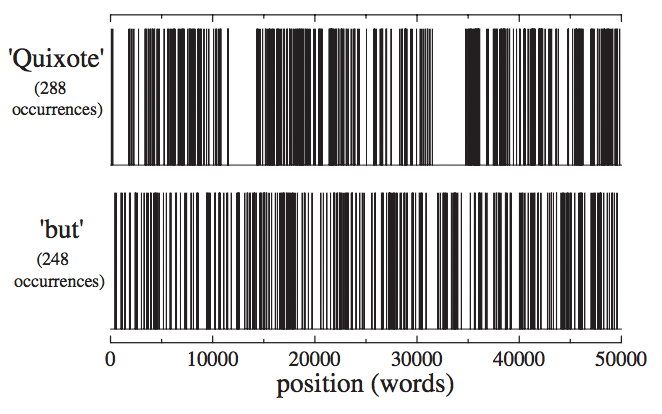
The test then simply boils down to computing how unlikely it is to see the given clustering pattern under the assumption that the sequence was produced randomly, or to be more specific under the assumption that the sequence was a sample from a geometric distribution. The more unlikely this is, the more aboutness we assign the word.
Does it work? Here are the top fifteen words for the concatenated Alice in Wonderland and Alice through the Looking Glass (together roughly the same size as the VMs):
| \(C\) | \(\sigma_\text{nor}\) |
|---|---|
| knight | knight |
| queen | hatter |
| king | mouse |
| hatter | caterpillar |
| he | kitty |
| dumpty | dormouse |
| mouse | dumpty |
| turtle | kitten |
| dormouse | sheep |
| red | turtle |
| humpty | humpty |
| mock | king |
| caterpillar | mock |
| gryphon | gryphon |
| she | red |
\(C\) and \(\sigma_\text{nor}\) are two slightly different notions of relevance, based on the principle described above. We notice that there are certainly reasonable “subject” words shown. The word “alice” itself, what the book is nominally about, is not shown, and indeed does not get a positive score. This is an important key for interpreting the results: what we are getting is more akin to a list of keywords, than the single subject of the book. Topics that are discussed in specific sections of the book.
For more examples, the authors provide some results online for various texts from project Gutenberg.
Aboutness in the VMs
Why is this such an exciting technique for the VMs? Because all we’ve used is the large scale structure of the book. Imagine translating The Hound of the Baskervilles to German. The words, of course, would change completely. So would the grammar, and probably the style. But the level statistics, the occurrences, at least of the salient words, would remain largely the same. The word Hund in the German version would occur on different pages, and with a different frequency than the word Hound in the English, but the basic clustering behavior would remain the same. So, even if we can’t read German, we can at least get a reasonable idea for which words have high aboutness.
Cutting to the chase, here are top 50 Voynichese words with the highest aboutness for \(C\) and for \(\sigma_\text{nor}\):
| \(C\) | \(\sigma_\text{nor}\) |
|---|---|
| shedy | cthy |
| qokeedy | qol |
| qol | kchy |
| qokaiin | qokeedy |
| chor | cthol |
| cthy | * |
| qokedy | chor |
| chedy | shedy |
| qokeey | sho |
| sho | shaiin |
| qokai!n | qokaiin |
| al | okai!n |
| chol | cthor |
| s | qokedy |
| daiin | qoteedy |
| okai!n | qokchol |
| otedy | ctho |
| lchedy | cheo |
| cthol | otai!n |
| qoteedy | qotchy |
| otai!n | lchedy |
| dy | cthar |
| cheo | cheeo |
| qotchy | yky |
| qokar | chaiin |
| kchy | chan |
| dai!n | chdaiin |
| ol | cho |
| oteedy | otedy |
| okeey | qodaiin |
| oteey | qokai!n |
| dol | f |
| cthor | r!aiin |
| qokal | dain |
| dain | s |
| aiin | chedy |
| cho | qotchor |
| qotedy | opchy |
| cheody | kchor |
| ar | lkchey |
| chdy | qotchol |
| chaiin | qokeey |
| chody | lkeey |
| shey | chom |
| or | oteedy |
| qotaiin | chos |
| okedy | ckhy |
| qokey | al |
| qodaiin | ckhey |
| dar | qodar |
For this experiment, I used the Takahashi EVA transcription. Anything between curly brackets was replaced by a space, and any sequence of multiple special characters (!, *, %) was collapsed into one.
What does this tell us? Well not much, but a little. If the VMs is about anything, some paerts are likely about “shedy” and about “qokeedy”. More interestingly, note that most of the top words in the Alice example were nouns. That suggests that if these words refer to anything, they probably refer to concepts of some sort. Most of them perhaps function like nouns. Perhaps. I’ll finish up with some thoughts on how we can expand on this, but first, let’s look at another experiment the authors of this method did.
Aboutness at the character level
For their second experiment, the authors removed all whitespace from a book, and performed the analysis for all character strings, up to a particular length. I couldn’t reproduce their results with their algorithm as they describe it, but I came up with something that performs similarly. Here are the top substrings for our concatenated Alice, with all whitespace removed:
| count | \(\sigma_\text{norm}\) | \(C\) | |
|---|---|---|---|
| umpty | 106 | 5.46 | 48.38 |
| queen | 273 | 3.36 | 39.88 |
| mouse | 86 | 4.69 | 36.40 |
| theredqueen | 54 | 5.15 | 33.42 |
| thequeen | 143 | 3.67 | 33.30 |
| knight | 59 | 4.90 | 32.64 |
| thehatter | 52 | 5.08 | 32.38 |
| theknight | 41 | 5.02 | 28.91 |
| theki | 128 | 3.37 | 28.07 |
| humpt | 56 | 4.29 | 26.98 |
| tweedled | 60 | 4.08 | 26.00 |
| theking | 111 | 3.31 | 25.64 |
| themouse | 29 | 4.88 | 24.37 |
| dormouse | 40 | 4.37 | 24.04 |
| dtheking | 49 | 3.89 | 22.40 |
| humptydumpty | 53 | 3.78 | 22.28 |
| thecaterpillar | 26 | 4.48 | 21.06 |
| kitty | 25 | 4.51 | 20.92 |
| kitten | 26 | 4.45 | 20.86 |
| thedormouse | 35 | 4.08 | 20.86 |
| mockturtle | 56 | 3.52 | 20.68 |
On balance, it seems like most phrases detected start and end at a word boundary, and most complete phrases are indicative of what a local part of the text is about. I’ve highlighted where phrases start and end with a string that was a word (of more than three characters) in the original text. The highlighting doesn’t work perfectly, but it gives a decent impression, which we can use to interpret the VMs results.
“umpty”, incidentally, provides a good intuition for where the method fails. The character’s name “humpty dumpty” has high aboutness (C=22.28), but every time the string umpty occurs, it then immediately occurs again one character later (even though the string is relatively rare overall). This is such a non-random level of clustering that “umpty” gets a very high C-score.
The character level analysis of the VMs shows some interesting differences:
| count | \(\sigma_\text{norm}\) | \(C\) | |
|---|---|---|---|
| edyqo | 1503 | 4.01 | 117.28 |
| hedyqo | 790 | 3.62 | 74.31 |
| edyqok | 965 | 3.33 | 73.03 |
| chedy | 1247 | 2.95 | 69.16 |
| yqoke | 1033 | 3.05 | 66.41 |
| dyqoke | 628 | 3.20 | 55.66 |
| qokai | 578 | 2.98 | 48.12 |
| edyqol | 93 | 5.68 | 47.77 |
| hedyqok | 500 | 3.01 | 45.57 |
| edyqoke | 516 | 2.92 | 44.15 |
| keedy | 639 | 2.66 | 42.56 |
| yqokee | 580 | 2.72 | 41.86 |
| chedyqo | 451 | 2.93 | 41.70 |
| yqokain | 211 | 3.78 | 41.57 |
| shedy | 658 | 2.57 | 40.68 |
| holcho | 121 | 4.46 | 39.93 |
| eedyqo | 461 | 2.80 | 39.15 |
| eyqoke | 305 | 3.11 | 37.69 |
| yqokeed | 271 | 3.17 | 36.57 |
| cheod | 255 | 3.23 | 36.53 |
| edyqot | 308 | 2.96 | 35.14 |
| kainsh | 114 | 4.11 | 34.86 |
| heody | 244 | 3.11 | 33.88 |
| eeyqok | 270 | 3.00 | 33.67 |
| yqokeedy | 253 | 3.06 | 33.63 |
| aiincth | 106 | 4.08 | 33.46 |
| dyqoka | 391 | 2.62 | 32.64 |
| chold | 156 | 3.50 | 32.43 |
| hedyqol | 63 | 4.73 | 32.09 |
| haiin | 138 | 3.56 | 31.42 |
| okcho | 151 | 3.44 | 31.20 |
| edyqokee | 289 | 2.79 | 31.19 |
| shedyqo | 313 | 2.67 | 30.30 |
| edyqoka | 299 | 2.64 | 29.03 |
| eodyqo | 151 | 3.20 | 28.19 |
| hedyqoke | 239 | 2.75 | 27.84 |
| cholcho | 86 | 3.81 | 27.78 |
| qokedy | 273 | 2.62 | 27.39 |
| horcho | 85 | 3.77 | 27.25 |
| lshed | 247 | 2.67 | 27.02 |
| lched | 418 | 2.29 | 26.90 |
| odaiin | 345 | 2.40 | 26.56 |
| eeyqoke | 161 | 3.00 | 26.40 |
| qokaiin | 265 | 2.58 | 26.37 |
| daiincth | 63 | 4.04 | 26.18 |
| chedyqok | 278 | 2.51 | 25.74 |
| kainshe | 86 | 3.56 | 25.35 |
| keedyqo | 240 | 2.59 | 25.31 |
| chorc | 183 | 2.80 | 25.18 |
| yqokeey | 233 | 2.60 | 25.16 |
| dyqokeedy | 182 | 2.80 | 25.10 |
| eedyqok | 303 | 2.41 | 25.09 |
| yqokedy | 226 | 2.61 | 24.86 |
| hedyqokee | 132 | 3.06 | 24.77 |
| lshedy | 224 | 2.56 | 24.01 |
| holdai | 97 | 3.29 | 23.90 |
| eyqokee | 186 | 2.69 | 23.84 |
| olkai | 169 | 2.73 | 23.33 |
| holchol | 63 | 3.68 | 23.15 |
| ylche | 185 | 2.64 | 23.12 |
| okainsh | 78 | 3.43 | 23.02 |
| lchedy | 366 | 2.16 | 22.64 |
| edyqokai | 168 | 2.66 | 22.30 |
| chorcho | 69 | 3.48 | 22.25 |
| edyqokeedy | 163 | 2.67 | 22.23 |
| iincho | 223 | 2.44 | 22.18 |
| choda | 148 | 2.72 | 21.87 |
| otedy | 254 | 2.33 | 21.79 |
| tchyc | 43 | 3.96 | 21.73 |
| eyqoka | 181 | 2.53 | 21.32 |
| qotch | 221 | 2.37 | 20.99 |
| shedyqok | 207 | 2.39 | 20.71 |
| cholda | 93 | 3.00 | 20.54 |
| otcho | 158 | 2.55 | 20.35 |
| chord | 65 | 3.32 | 20.34 |
| keedyqok | 167 | 2.51 | 20.29 |
| hedyo | 354 | 2.05 | 20.15 |
| dyqokedy | 164 | 2.49 | 19.90 |
| keody | 141 | 2.60 | 19.81 |
| chaiin | 83 | 3.02 | 19.70 |
| orcth | 52 | 3.44 | 19.42 |
| kainch | 189 | 2.36 | 19.31 |
| olched | 188 | 2.35 | 19.24 |
| eodyqok | 92 | 2.88 | 19.24 |
| holdaiin | 72 | 3.09 | 19.18 |
| eodai | 132 | 2.58 | 19.02 |
| aiincho | 196 | 2.29 | 18.76 |
| cheody | 141 | 2.51 | 18.76 |
| chedyqol | 37 | 3.70 | 18.71 |
| keedyqoke | 98 | 2.75 | 18.44 |
| okeedyqo | 166 | 2.37 | 18.38 |
| dycho | 191 | 2.28 | 18.30 |
| lkaiin | 137 | 2.49 | 18.21 |
| chedyqoke | 127 | 2.53 | 18.06 |
| eodyo | 136 | 2.47 | 17.98 |
| olshedy | 107 | 2.64 | 17.92 |
| horda | 55 | 3.19 | 17.88 |
| odych | 203 | 2.21 | 17.77 |
| okainshe | 62 | 3.06 | 17.73 |
| shedyqoke | 101 | 2.66 | 17.72 |
| yqokaiin | 184 | 2.26 | 17.71 |
| cthol | 82 | 2.82 | 17.66 |
| eyqokeey | 100 | 2.66 | 17.62 |
| okeod | 124 | 2.50 | 17.62 |
| lshee | 126 | 2.49 | 17.60 |
| qokedyq | 84 | 2.78 | 17.49 |
| lchedyqo | 137 | 2.42 | 17.42 |
| qokedyqo | 83 | 2.76 | 17.22 |
| eyqokai | 124 | 2.47 | 17.17 |
| keeyq | 181 | 2.23 | 17.14 |
| inche | 664 | 1.65 | 17.09 |
| eeyqokee | 98 | 2.62 | 17.02 |
| edyche | 255 | 2.03 | 17.00 |
| otchyc | 28 | 3.72 | 16.97 |
| hotch | 53 | 3.10 | 16.90 |
| edyqokedy | 139 | 2.37 | 16.89 |
| aiinctho | 43 | 3.29 | 16.88 |
| eeody | 150 | 2.31 | 16.82 |
| edyqokain | 86 | 2.69 | 16.81 |
| eylch | 86 | 2.69 | 16.81 |
| chody | 177 | 2.21 | 16.78 |
| cholchol | 47 | 3.19 | 16.77 |
| sheod | 122 | 2.44 | 16.72 |
| hokch | 75 | 2.78 | 16.67 |
| eedyqokee | 116 | 2.46 | 16.56 |
| ncthy | 31 | 3.55 | 16.56 |
| qoteed | 83 | 2.69 | 16.50 |
| heyqok | 264 | 1.99 | 16.48 |
| lkain | 120 | 2.42 | 16.37 |
There’s a lot to note here.
Firstly, the C scores are bigger than any observed in a natural language text of this size. This indicates a much more clustered non-randomness in how substrings occur within the text. It was known already that there was more structure to the VMs text than to natural language, but it’s interesting to see that this leads to more clustering. Even if the method by which the text was composed is random, this suggest that strongly non-stationary process. In short, you can tell by the local properties of the text which part of the book you’re in (better than you can with a natural language book). If it is generated text, the generator either has a very sophisticated long-term memory, or the author reconfigured the generator between chapters.
Secondly, we are getting a lot more results. In both experiments, I started with the 200 substrings with the highest C score. For any pair \((s, l)\) of these, where \(s\) contained \(l\), I remove \(l\) if its score is more than 2.5 below that of \(s\), otherwise I remove \(s\). I think we can hypothesize that the VMs text is somehow less “transitive” with its substrings than natural language. For instance, if “dormouse” occurs in a clustered way throughout Alice, then we can assume that most of its substrings (ormouse, rmous, dormo), will follow exactly the same pattern. Only a rare few (mouse, use) are words meaning something different, and are likely to show a different clustering pattern. In Voynichese, it seems, a random substring of a specific word, is much less likely to follow the clustering behavior of its superstring. We can see this from the top two entries: “hedyqo” has a high score, but nowhere near as high as its substring “edyqo”. In other words “edyqo” occurs many more times, and in many different words than just in “hedyqo” alone.
Quite what the Voynich “words” mean, and what role substrings play in the text is an open question. Hopefully, I’ll come back to that in a later post.
A promising method
Of course, it doesn’t do us much good to know that the VMs is about “shedy” if we don’t know what that means. But it does paint a promising picture of a more structured approach to cracking the VMs. Let’s start by stating our assumptions:
- The VMs contains, in some form, possibly encoded, meaningful text in natural language (the plaintext).
- The words of the VMS, i.e. strings separated by whitespace, map to plaintext words, phrases, or at least broad concepts.
- Two occurrences of the same Voynichese word, more likely than not, mean the same thing.
There are certainly plausible scenarios for these assumptions to be violated, but as assumptions go in Voynich-land, these are pretty light-weight.
Given these assumptions, we know the level statistics are likely to be informative, and we can take the lists above as roughly “correct”. But that’s not where their usefulness ends. Remember that the words with the highest aboutness are likely to be nouns. Similarly, parts of speech like verbs and articles are likely to have very uniform distributions. However noisy, the level statistics, and similar features allow us to make an informed guess about the parts of speech of different Voynich words.
Imagine the following experiment:
- Take a book in language A, and tag the words with a set of simplified POS tags, like {noun, verb, numeral, other}.
- For each word, collect a series of measurements in the vein of level statistics: features that are largely invariant to cross-language translation.
- Train a simple (probabilistic) classifier to classify words by their POS tags
- Take a book in language B, collect the features for each word and use the classifier to tag the words.
Even if we filter everything but the 100 words the classifier is most certain about, it would still provide great insight into the grammatical structure of the VMs. Considering how many cyphers were cracked just by identifying a single numeral in the cyphertext, a provisional POS-tagger seems like a great luxury.
Code and links
The code is available on GitHub. It’s a weekend project, so it’s far from perfect. If you’d like to play around with it, let me know, I’ll help you get set up.
Similar work was performed, with different methods, in the article Keywords and Co-Occurrence Patterns in the Voynich Manuscript: An Information-Theoretic Analysis, published in PLOS One in 2013.