Proving the spectral theorem
- 8 Oct 2021
- part 1
- 2
- 4
- 5
- get the book!
When I started this series of blogposts, it was not meant to be a four-parter. I was going for an explanation of Principal Component Analysis that was simple, but that also didn’t skip any steps. I was frustrated with other explanations that leave things out, or require the reader to take things at face value.
This part illustrates why that so often happens. In this part we will prove the spectral theorem, which we introduced last time. This is very much the dark heart of PCA: the one result from which everything else follows, so it pays to understand it properly. The drawback is that the proof of the spectral theorem adds a boatload of preliminaries to the story.
Suddenly, just to understand this one statement, we need to understand determinants, the characteristic polynomial, complex numbers, vectors and matrices and the fundamental theorem of algebra. All interesting, of course, and worth knowing about, but it’s a lot of baggage if you just want to know how PCA works. So I decided to move it all into one self-contained part of the series. If this is too much for you, you can take the spectral theorem at face value, and move on to the final part, which is about implementing PCA with the singular value decomposition.
Restating the spectral theorem
In the last part, we learned the following.
An orthogonal matrix is a square matrix whose columns are mutually orthogonal unit vectors. Equivalently, an orthogonal matrix is a matrix $\rc{\P}$ for which $\rc{\P}^{-1} = \rc{\P}^T$.
Any square matrix $\bc{\A}$ is orthogonally diagonalizable if there exists an orthogonal matrix $\rc{\P}$ and a diagonal matrix $\bc{\D}$ such that $\bc{\A} = \rc{\P}\bc{\D}\rc{\P}^T$. A matrix $\bc{\A}$ is symmetric if $\bc{\A} = \bc{\A}^T$.
A matrix is orthogonally diagonalizable if and only if it is symmetric.
Previously, we saw how much follows from this one simple theorem. If we take this to be true, we get eigenvectors, whitening and principal components.
In the rest of this blog post we’ll build a toolkit step by step, with which to analyze this problem. At the end, we’ll return to the theorem and apply our tools to prove it.
Our first tool is a very useful function of a matrix: the determinant.
Determinants
The determinant started life long before linear algebra. As early as the 3rd century BCE, the function was used as a property of a set of linear equations, that would allow you to determine whether the equations had a solution.
Later, determinants were studied as functions in their own right. In this context, they were seen as very opaque and abstract. Something that was useful in higher mathematics, but hard to explain to the lay person. It wasn’t until matrices become popular, and in particular the view of a matrix representing a geometric transformation, that determinants finally acquired an intuitive and simple explanation.
That explanation—apart from some subtleties which we’ll discuss later—is that given a square matrix $\bc{\A}$, the determinant of $\bc{\A}$ is a number that expresses how much $\bc{\A}$ inflates the space it transforms.
For an example, here are three different ways that a matrix might transform space to squish and stretch in different directions.

In the first, everything is stretched equally in all directions by a factor of 2. That means that a square with area 1 in the original (a unit square) has area 4 after the transformation by $\bc{\A}$ (since both its sides are doubled). This is what we mean by inflating space: the determinant of $\bc{\A}$ is 4 because transforming something by $\bc{\A}$ increases its area by a factor of 4. In the second example, We stretch by 1.1 in one direction, and shrink to 0.5 in the other. The result is that that a unit square in the original ends up smaller after the transformation: the determinant of $\bc{\B}$ is $0.5 \times 1.1 = 0.55$.
The third example is a little trickier. The Mona Lisa is again squished and stretched in different directions, but these are not aligned with the axes. The area of the unit square seems to be getting a little smaller, but how can we tell by how much exactly?
Before we dig into the technical details, let’s first look at why it is worth doing so. Why is it so important to know by how much a matrix inflates space? There are many answers, but in the context of this series, the most important reason to care about the determinant is that it gives us a very convenient characterization of invertible matrices.
An invertible matrix is simply a matrix whose transformation is invertible. That is, after we apply the transformation $\y \leftarrow \bc{\A}\x$ we can always transform $\y$ back to $\x$, and end up where we started.
When is a matrix not invertible? When multiple inputs $\x$ are mapped to a single output $\y$. In linear transformations, this happens when the input is squished so much in one direction, that the resulting space has a lower dimensionality than the original.

We don’t need to know how to compute the determinant to know what its value is in this case. The unit square is mapped to a line segment, so its area goes from $1$ to $0$. This is how the determinant helps us to characterize invertible matrices: if the determinant is non-zero, the matrix is invertible, if the determinant is zero the matrix is not invertible, or singular.
Computing the $2\times 2$ determinant
Using this definition, it’s pretty straightforward to work out what the formula is for the determinant of a matrix $\bc{\A}$ that transforms a 2D space. We’ll start by drawing a unit square, and labeling the four corners:

The corner points $(0,0)$, $(0,1)$ $(1,0)$ and $(1,1)$ can be transformed by multiplying them by $\bc{\A}$. we know that under a linear operation like this, line segments stay line segments, so the four edges of the square are transformed to line segments, and the resulting figure between the four points must be a quadrilateral. We also know that parallelism is preserved: two line segments that were parallel before the transformation are parallel after. Lastly, we know that the origin stays where it is, unless we apply a translation, so corner $(0, 0)$ is not affected by the transformation. All this means that the picture after the transformation will look something like this.

A parallelogram with one corner touching the origin. The determinant tells us the ratio between the area of the paralellogram and the original square. Since the original square has area $1$, the area of the parallelogram is the determinant of $\bc{\A}$.
Working this out requires only a small amount of basic geometry. Here’s the simplest way to do it.
We first name the four elements of our matrix:
\[\bc{\A} = \begin{pmatrix} a & b \\ c & d \end{pmatrix}\]We can now name the four corners of our parallelogram in terms of these four scalars, by multiplying the corner points of the unit square by $\bc{\A}$:
\[\begin{matrix} \times & \begin{pmatrix}0\\ 0\end{pmatrix} & \begin{pmatrix}1\\ 0\end{pmatrix} & \begin{pmatrix}0\\ 1\end{pmatrix} & \begin{pmatrix}1\\ 1\end{pmatrix} \\ \bc{\begin{pmatrix} a & b \\ c & d \end{pmatrix}} & \begin{pmatrix}0\\ 0\end{pmatrix} & \begin{pmatrix}a\\ c\end{pmatrix} & \begin{pmatrix}b\\ d\end{pmatrix} & \begin{pmatrix}a+b\\ c+d\end{pmatrix} \\ \end{matrix}\]This gives us the following picture.

Here we can see the area of the paralellogram clearly: there is one large rectangle of area $\oc{ad}$. To get from this area to the area of our parallelogram, we should subtract the area of the green triangle in the bottom, which is part of the rectangle but not the parallelogram.
But then, there’s a green triangle at the top, with the same size, which is (mostly) part of the parallelogram but not of the rectangle, so these cancel each other out. We follow the same logic for the red triangles.
Putting all this together, the rectangle with area $\oc{ad}$ has the same area as the parallellogram, except that we are overcounting three elements (outlined in blue): the two small triangles in the box at the top, which are not part of the paralellogram, and the overlap between the green and the red triangles, which we’ve counted twice. These three overcounted elements add up precisely to the box at the top-right, which has area $\rc{bc}$.
So, the area of the paralellogram, and therefore the determinant of the matrix $\bc{\A}$ is $\oc{ad} - \rc{bc}$. Or, in words: the determinant of a $2 \times 2$ matrix is the diagonal product minus the antidiagonal product.
We will write the determinant with two vertical bars around the matrix values (removing the matrix parentheses for clarity):
\[\left |\begin{array} ~a & b \\ c & d \end{array}\right | = ad - bc \p\]Negative determinants
In the picture we drew to derive this, $ad$ was bigger than $bc$, so the determinant was positive. But this is not guaranteed. Look at the two column vectors of our matrix. If we flip them around then the determinant becomes:
\[\left |\begin{array} ~b & a \\ d & c \end{array}\right | = bc - da \p\]This is the same quantity as before, but negative. Areas can’t be negative, so how do we interpret this?
The magnitude remains the same, so the simplest solution is just to adjust our definitions: the absolute value of $|\bc{\A}|$ is the amount by which $|\bc{\A}|$ inflates space.
However, in many situations, the idea of a “negative area” actually makes a lot of sense. Consider, for instance, this graph of the velocity of a train along a straight track from one station to another and back again:

Here, we’ve used a negative velocity to represent the train traveling backwards. If you’ve done some physics, then you’ll know that the area under the speed curve represents distance traveled. Here we have two options: we can look at the absolute value of the area, and see that the train has, in total, travelled twice the distance between the stations. We can also take areas below the horizontal axis to be negative. Then, their sum tells us that the total distance between the train’s starting point and its final position is exactly zero.
All this is just to say, if you need positive areas, just take the magnitude of the determinant, but don’t be too quick to throw away the sign. It may have some important meaning in your particular setting. For our purposes, we’ll need these kinds of areas when we want to think about determinants for larger matrices.
We’ll call this kind of positive or negative area a signed area, or signed volume in higher dimensions. You can think of the parallelogram as a piece of paper. If $\bc{\A}$ stretches the paper, but doesn’t flip it around, the singed area is positive. If the paper is flipped around, so that we see the reverse, the area is negative. If you flip the paper around twice, the sign becomes positive again.
Towards $n \times n$ determinants
Let’s think about what we’ll need to generalize this idea to $3 \times 3$ matrices and beyond, to general $n \times n$ matrices. The basic intuition generalizes: we can start with a unit (hyper)cube in $n$ dimensions. A square matrix transforms this into an analogue of a parallelogram, called a parallellotope.
For a given dimensionality we can define a notion of $n$-volume. The 3-volume is simply the volume we already know. The $n$-volume of an n-dimensional “brick”, the analogue of a rectangle, is the product of its extent in each direction: height times width times length and so on in all directions. This means that the unit hypercube, which has sides of length 1 in all directions, always has $n$-volume 1.
We will assume, by analogy with the $2 \times 2$ case, that the determinant of an $n \times n$ matrix $\bc{\A}$ is the $n$-volume of the parallellotope that results when we transform the unit hypercube by $\bc{\A}$.
We can generalize a few useful properties from the $2 \times 2$ case. The columns of $\bc{\A}$ are those vectors that describe the edges that touch the origin. We’ll call these the basis vectors of the parallelogram/-tope.

The proof we gave above for the $2 \times 2$ determinant is very neat, but it isn’t very easy to generalize to the $n \times n$ case in an intuitive way.
Instead, let’s re-prove our result for the $2 \times 2$ case in a way that’s easier to generalize. We’ll need to convince ourselves of three properties of the area of a parallellogram.
The first property we need is that if we move one of the sides of the parallelogram without changing its direction, the area of the parallellogram remains the same. This is easy to see visually.

Note that shifting one of the sides always adds a triangle to the parallellogram and takes away a triangle of the same size, so the total stays the same. The last example is particularly relevant: we can shift the parallelogram so that one of its edges is aligned with one of the axes. If we do this twice, we’ll have a rectangle with an area equal to that of the original parallellogram.
What does this look like in the original matrix? Remember that the columns of the matrix are the two edges of the parallelogram that touch the origin. Shifting one of them in this way is equivalent to adding or subtracting a small multiple of the other to it.

That is, if we take one of the columns of $\bc{\A}$, multiply it by any non-zero scalar, and add it to another column, the area of the resulting parallelogram is unchanged. If we name the column vectors $\bc{\v}$ and $\bc{\w}$, and write $|\,\bc{\v}, \bc{\w}\,|$ for the determinant of the matrix with these column vectors, then we have
\[|\,\bc{\v}, \bc{\w}\,| = |\,\bc{\v} + \rc{r}\bc{\w}, \bc{\w}\,| \;\;\text{for any nonzero $\rc{r}$.}\]This kind of transformation is called a skew or a shear, so we’ll call this property skew invariance: the area of a parallelogram is skew invariant.
The second property we need, is that if we take one of the column vectors of the matrix, say $\bc{\v}$, and write it as the sum of two other vectors $\bc{\v} = \oc{\v}^1 + \oc{\v}^2$, then the area of the paralellogram made by basis vectors $\bc{\v}, \bc{\w}$ is the sum of the area of the two smaller parallelograms with basis vectors $\oc{\v}^1, \bc{\w}$ and $\oc{\v}^2, \bc{\w}$ respectively.
This is easy enough to see if $\oc{\v}^1$ and $\oc{\v}^2$ point in the same direction. Then the two smaller parallelograms together simply combine to form the larger one.
If they don’t point in the same direction, we can skew them until they do. Since we’ve already shown that the area is skew invariant, none of this changes the area of the paralellogram.

Symbolically, this means that if we break one of the vectors in a matrix into a sum of two other vectors, then the determinant distributes over that sum:
\[|\;\oc{\v}^1 + \oc{\v}^2, \bc{\w}\;| = |\;\oc{\v}^1, \bc{\w}\;| + |\;\oc{\v}^2, \bc{\w}\;| \p\]We won’t need it here, but we can also show that multiplying one of the vectors ny some scalar scales the determinant by the same value. These two properties together are called multilinearity: the area of a paralellogram is a multilinear function of the basis vectors. It’s a linear function of one of its arguments if we keep the others fixed.
We need one more property: if we start with a parallelogram with basis vectors $\bc{\v}, \lbc{\w}$, and we flip around the vectors, $\lbc{\w}, \bc{\v}$, what happens to the area? If we look at the picture of the parallellogram, at first, it’s difficult to see that anything changes at all. The two basis vectors are still the same. To see what happens, we need to look at the operation of the matrix with these vectors as its columns.
The matrix with columns $\bc{\v}, \lbc{\w}$ maps the horizontal unit vector $\e_h$ to $\bc{\v}$, and the vertical unit vector $\e_h$ to $\lbc{\w}$. For the matrix with the columns swapped, we reverse this mapping. We get the same, parallelogram, but it's as if we've turned it over. Since the unit square has positive area, the flipped-over paralellogram has negative area.

Put simply, swapping basis vectors around maintains the magnitude of the area of a parallellogram, but changes the signs.
\[|\;\bc{\v}, \lbc{\w}\;| = - |\;\lbc{\w}, \bc{\v}\;| \p\]We call this property alternativity. As in, the area of a parallelogram is and alternating function of its basis vectors.
With these three properties: skew invariance, multilinearity and alternativity, we can work out our new proof of the determinant formula. First, using multilinearity, we write the first column of matrix $\bc{\A}$ as the sum of two vectors:
\[\left | \begin{array} ~a & b \\ c & d\end{array} \right | = \left | \begin{array} ~a & b \\ \kc{0} & d\end{array} \right | + \left | \begin{array} ~\kc{0} & b \\ c & d\end{array} \right | \p\]We’ll call this kind of vector, where only one element is non-zero, a simple vector. Here’s a visualization of that step.

Next, we use the property of skew invariance to subtract multiples of these new columns from the others. We use whatever multiple is required to make the rest of the row $0$. The other rows are unaffected, since these all have $0$’s in the original column.
\[\left | \begin{array} ~a & b \\ \kc{0} & d\end{array} \right | + \left | \begin{array} ~\kc{0} & b \\ c & d\end{array} \right | = \left | \begin{array} ~a & \kc{0} \\ \kc{0} & d\end{array} \right | + \left | \begin{array} ~\kc{0} & b \\ c & \kc{0}\end{array} \right |\p\]Visually, that looks like this.

We have two parallelograms with one edge axis-aligned, and we simply skew them so that the other edge is axis-aligned as well. the area we’re looking for is now the sum of two rectangles, one of which of facing away from us.
For the first term, we can work out the determinant easily. A diagonal matrix transforms the unit cube to a rectangle, so we just multiply the values along the diagonal: $ac$. For the second term, we have an anti-diagonal matrix. We can turn this into a diagonal matrix by swapping the two columns. By the property of alternativity, this changes the sign of the area, so the resulting signed area is $-bc$:
\[\left | \begin{array} ~a & \kc{0} \\ \kc{0} & d\end{array} \right | + \left | \begin{array} ~\kc{0} & b \\ c & \kc{0}\end{array} \right | \quad=\quad \left | \begin{array} ~a & \kc{0} \\ \kc{0} & d\end{array} \right | - \left | \begin{array} ~b & \kc{0} \\ \kc{0} & c\end{array} \right | \quad=\quad ac - bc \p\]This was certainly a more involved way of deriving the formula for the area of a polygon, but the benefit here is that this method generalizes very easily to higher dimensions.
Determinants for $n\times n$ matrices
We’ll start with the three properties we used above, and see how they generalize to higher dimensions.
Skew invariance also holds in higher dimensions. If we have an $n \times n$ matrix $\bc{\A}$ with $n$ column vectors $\bc{\a}^1, \ldots, \bc{\a}^n$ adding a multiple of one to another does not change the volume of the resulting parallelotope. For instance:
\[| \bc{\u}, \bc{\v}, \bc{\w} | = | \bc{\u} + \rc{r}\bc{\v}, \bc{\v}, \bc{\w} |\]Multilinearity also carries over in the same way. We can break one of the column vectors up into a linear combination of two (or more) other vectors and the area of the resulting paralellotope breaks up in the same way. For instance:
\[| \oc{\u}^1 + \oc{\u}^2, \bc{\v}, \bc{\w} | = | \oc{\u}^1 , \bc{\v}, \bc{\w} | + | \oc{\u}^2, \bc{\v}, \bc{\w} |\]Finally, alternativity. This requires a little more care. You’d be forgiven for thinking that since we have a higher-dimensional space, we now have more ways for our paralellotope to orient as well. We thought of our paralellogram as a piece of paper which could lie on the table in two ways. If we hold a parallellotope up in space, we can rotate it in all sorts of directions.
But the metaphor of a piece of paper is slightly misleading. When we flip a piece of paper upside-down, we rotate it, but that’s not what really happens when we swap the basis vectors of the paralellogram. What really happens is that we turn the piece of paper inside-out: we flip it by pulling the right edge to the left and the left edge to the right.
A better metaphor is a mirror. Imagine standing in front of a mirror and holding up your right hand, palm forward.
It looks like your twin inside the mirror is holding up their left hand, with the thumb facing in the opposite direction. But if the mirror flips the image left-to-right, why doesn’t it flip the image upside-down as well, even if we rotate the mirror? How does the mirror keep track of which direction the floor is?
The answer is that the mirror doesn’t flip the image left-to-right. It flips it back-to-front. In a manner of speaking, it pulls the back of your hand forward and the front of your hand backwards until the whole hand is flipped.
Putting the mirror to your side will flip you left-to-right, also turning your right hand into a left hand. Putting the mirror on the floor and standing on it turns you upside-down, and again turns the right hand into a left hand. If you use two mirrors, one in front of you and one below, you are flipped back-to-front and upside-down, and if you look at this mirror-twin, you’ll see that their hand has been flipped twice, to become a right hand again.
The result is that we still have only two orientations. Each time anything gets mirrored, it gets pulled inside out along some line, and the sign of the volume changes. If it gets flipped an even number of times the sign stays the same, and if it gets flipped an odd number of times, the sign changes.
This means that alternativity in higher dimensions is defined as follows: if we swap around any two columns in a matrix, we flip the space (along a diagonal between the two corresponding axes). Therefore, the magnitude of the determinant stays the same, but the sign changes. If we flip two more axes, the sign changes back. For instance:
\[|\; \u, \bc{\v}, \lbc{\w} \;| = - |\; \bc{\v}, \u, \lbc{\w} \;| = |\; \lbc{\w}, \u, \bc{\v} \;| \p\]That’s our three properties in place. Finally, before we start our derivation, note that in the $2 \times 2$ case, our ultimate aim was to work the matrix determinant into a sum of determinants of diagonal matrices. The idea was that the determinant of a diagonal matrix is easy to work out.
That’s still true in higher dimensions: the columns of a diagonal matrix $\bc{\A}$ each map one of the unit vectors to a a basis vector of length $\bc{A}_{ii}$ that lies along the $i$-th axis. Together these form the sides of an $n$-dimensional “brick” whose volume is just these lengths multiplied together. So the plan stays the same: use our three properties to rewrite the determinant into a sum of determinants of diagonal matrices.
We’ll work this out for a $3 \times 3$ matrix explicitly to keep the notation simple, but the principle holds for any number of dimensions.
We start by taking the first column of our matrix, and breaking it up into three simple vectors.
\[\left | \begin{array} ~a & b & c\\ d & e & f\\ g & h & i \end{array} \right | = \rc{\left | \begin{array} ~a & b & c\\ \kc{0} & e & f\\ \kc{0} & h & i \end{array} \right |} + \gc{\left | \begin{array} ~\kc{0} & b & c\\ d & e & f\\ \kc{0} & h & i \end{array} \right |} + \bc{\left | \begin{array} ~\kc{0} & b & c\\ \kc{0} & e & f\\ g & h & i \end{array} \right |}\]As before, we’ve broken our parallellotope into three parallellotopes, each with one of their edges axis-aligned. Next, we subract multiples of the first column from each of the other columns to turn the rows into vectors with only one non-zero element.
\[\rc{\left | \begin{array} ~a & \kc{0} & \kc{0}\\ \kc{0} & e & f\\ \kc{0} & h & i \end{array} \right |} + \gc{\left | \begin{array} ~\kc{0} & b & c\\ d & \kc{0} & \kc{0}\\ \kc{0} & h & i \end{array} \right |} + \bc{\left | \begin{array} ~\kc{0} & b & c\\ \kc{0} & e & f\\ g & \kc{0} & \kc{0} \end{array} \right |}\]This doesn’t yet look quite as simple as it did in our previous example, but we can go back to the first step and break the second column vector of each term into simple vectors as well. For the first term that looks like this:
\[\rc{\left | \begin{array} ~a & \kc{0} & \kc{0}\\ \kc{0} & e & f\\ \kc{0} & h & i \end{array} \right |} = \rc{\left | \begin{array} ~a & \kc{0} & \kc{0}\\ \kc{0} & \kc{0} & f\\ \kc{0} & \kc{0} & i \end{array} \right |} + \rc{\left | \begin{array} ~a & \kc{0} & \kc{0}\\ \kc{0} & e & f\\ \kc{0} & \kc{0} & i \end{array} \right |} + \rc{\left | \begin{array} ~a & \kc{0} & \kc{0}\\ \kc{0} & \kc{0} & f\\ \kc{0} & h & i \end{array} \right |}\]In the first term, one of the column vectors is zero. This means the parallelotope becomes a parallelogram, with $0$ volume, so we can remove this term. For the other two, we apply the multilinear property to sweep the rows, and we get
\[\rc{\left | \begin{array} ~a & \kc{0} & \kc{0}\\ \kc{0} & e & f\\ \kc{0} & h & i \end{array} \right |} = \rc{\left | \begin{array} ~a & \kc{0} & \kc{0}\\ \kc{0} & e & \kc{0} \\ \kc{0} & \kc{0} & i \end{array} \right |} + \rc{\left | \begin{array} ~a & \kc{0} & \kc{0}\\ \kc{0} & \kc{0} & f\\ \kc{0} & h & \kc{0} \end{array} \right |}\]The logic is the same for the other terms. If we ignore the zeros that we added, we end up with an $2 \times 2$ submatrix, to which we can apply the same trick again to turn each term into two more terms. If we do this we get six terms in total.
\[\rc{\left | \begin{array} ~a & \kc{0} & \kc{0}\\ \kc{0} & e & \kc{0} \\ \kc{0} & \kc{0} & i \end{array} \right |} + \rc{\left | \begin{array} ~a & \kc{0} & \kc{0}\\ \kc{0} & \kc{0} & f\\ \kc{0} & h & \kc{0} \end{array} \right |} + \gc{\left | \begin{array} ~\kc{0} & b & \kc{0} \\ d & \kc{0} & \kc{0}\\ \kc{0} & \kc{0} & i \end{array} \right |} + \gc{\left | \begin{array} ~\kc{0} & \kc{0} & c\\ d & \kc{0} & \kc{0}\\ \kc{0} & h & \kc{0} \end{array} \right |} + \bc{\left | \begin{array} ~\kc{0} & b & \kc{0}\\ \kc{0} & \kc{0} & f\\ g & \kc{0} & \kc{0} \end{array} \right |} + \bc{\left | \begin{array} ~\kc{0} & \kc{0} & c\\ \kc{0} & e & \kc{0}\\ g & \kc{0} & \kc{0} \end{array} \right |}\]The result is that we have separated the determinant into several terms, so that for each, the matrix in that term has only one non-zero element in each row and each column. The structure of the non-zero values is that of a permutation matrix, with the exception that permutation matrices contain only $1$s and $0$s. These are like the original matrix $ \bc{\A}$ with a permutation matrix used to mask out certain values.
In fact, what we have done is to enumerate all possible permutations. We started by creating one term for each possible choice for the first column, and then for each term we separated this in to the remaining two choices for the second column (after which the choice for the third column was fixed as well).
This idea naturally generalizes to higher dimensions. Moving from left to right, we pick one element of each column and zero out the rest of its column and row. At each subsequent step we limit ourselves to whatever non-zero elements remain. We sum the determinants of all possible ways of doing this.
We can now turn each of these matrices into a diagonal matrix, by swapping around a number of columns. By the property of alternativity, this doesn’t change the magnitude of the determinant, only the sign: for an even number of swaps, it stays the same and for an odd number it flips around. This gives us
\[\rc{\left | \begin{array} ~a & \kc{0} & \kc{0}\\ \kc{0} & e & \kc{0} \\ \kc{0} & \kc{0} & i \end{array} \right |} - \rc{\left | \begin{array} ~a & \kc{0} & \kc{0}\\ \kc{0} & f & \kc{0} \\ \kc{0} & \kc{0} & h\end{array} \right |} - \gc{\left | \begin{array} ~b & \kc{0} & \kc{0} \\ \kc{0} & d & \kc{0}\\ \kc{0} & \kc{0} & i \end{array} \right |} + \gc{\left | \begin{array} ~c & \kc{0} & \kc{0} \\ \kc{0} & d & \kc{0}\\ \kc{0} & \kc{0} & h \end{array} \right |} + \bc{\left | \begin{array} ~b & \kc{0} & \kc{0}\\ \kc{0} & f & \kc{0} \\ \kc{0} & \kc{0} & g \end{array} \right |} - \bc{\left | \begin{array} ~c & \kc{0} & \kc{0} \\ \kc{0} & e & \kc{0}\\ \kc{0} & \kc{0} & g\end{array} \right |} \p\]And since the determinant of a diagonal matrix is simply the diagonal product, as we worked out earlier, we get
\[\left | \begin{array} ~a & b & c\\ d & e & f\\ g & h & i \end{array} \right | = \rc{aei} - \rc{afh} - \gc{bdi} + \gc{cdh} + \bc{bfg} + \bc{ceg} \p\]To generalize this to $n$ dimensions, we represent a permutation of of the first $n$ natural numbers with the symbol $\sigma$. For instance $\sigma = \langle 1, 5, 4, 3, 2\rangle$. We’ll call the sign of a permutation, $\text{sign}(\sigma)$, $-1$ if the permutation can be placed in the correct order with an odd number of swaps and $1$ if this can be done with an even number of swaps.
Then, the process we described above leads to the following formula for the determinant:
$$ |\bc{\A}| = \sum_\sigma \text{sign}(\sigma) \prod_i \bc{A}_{\sigma(i), i} $$
where the sum is over all permutations of the first $n$ natural numbers, and the product runs from $1$ to $n$.
Note that for each term in our sum, corresponding to the permutation $\sigma$, the value $\bc{A}_{\sigma(i), i}$ marks out one of the elements that we haven't zeroed out. The value $\prod_i \bc{A}_{\sigma(i), i}$ is the product of all these values.
This is called the Leibniz formulation of the determinant.
The determinant is a powerful tool, with many uses. Here, we only care about one of them: it lets us characterize whether a matrix is invertible or not. The determinant is precisely zero if and only if the matrix is not invertable. The reason we care about this, is that it will lead to a very useful way of characterizing the eigenvalues: the characteristic polynomial of a matrix.
The characteristic polynomial
Let’s start with how we originally characterized eigenvalues in part 2. There, we said that an eigenvector of a matrix $\bc{\A}$ is any vector $\rc{\v}$ for wich the direction doesn’t change, under operation of the matrix. The magnitude can change, and the increase of that magnitude we call the eigenvalue $\bc \lambda$ corresponding to the eigenvector.
To summarize, for any eigenvector $\rc \v$ and its eigenvalue $\bc{\lambda}$ of $\bc \A$, we have
\[\bc{\A}\rc{\v} = \bc{\lambda}\rc{\rc{\v}} \p\]Moving the right-hand-side over to the left, we get
\[\bc{\A}\rc{\v} - \bc{\lambda}\rc{\rc{\v}} = {\mathbf 0} \text{,}\]where both sides are vectors (with a vector of zeros on the right). To allow us to manipulate the left hand side further we rewrite $\bc{\lambda}\rc{\v}$ as $(\bc{\lambda}\I)\rc{\v}$. This gives us:
$$\begin{align*} \bc{\A}\rc{\v} - \bc{\lambda}\I\rc{\rc{\v}} &= {\mathbf 0} \\ (\bc{\A} - \bc{\lambda}\I)\rc{\rc{\v}} &= {\mathbf 0} \p \end{align*}$$
This last line is basically a linear problem of the form $\bc{\M}\rc{\v} = \mathbf 0$, with $\bc{\M} = (\bc{\A} - \bc{\lambda}\I)$. The solutions to this problem, the set of all vectors $\bc{\v}$ that we can multiply by $\bc{\M}$ to get the null vector $\mathbf 0$ are called the null space of $\bc{\M}$. What we have just shown is that any eigenvector of $\bc \A$ with eigenvalue $\bc \lambda$ must be in the null space of the matrix $\bc{\A} - \bc{\lambda}\I$.
This is where invertibility and the determinant come in: if $\bc \M$ is invertible, it can only map one point to any other point. Every matrix maps $\mathbf 0$ to $\mathbf 0$, so for any invertible matrix the null space consists only of the point $\mathbf 0$. The only matrices with more interesting null spaces are non-invertible matrices. Or, matrices with determinant $0$.
So, now we can tie it all together. Choose some scalar value $\bc \lambda$. If we have
\[\left | \; \bc{\A} - \bc{\lambda}\I \;\right | = 0\]then the matrix $\bc{\A} - \bc{\lambda}\I$ has a non-trivial null-space, and $\bc \lambda$ is an eigenvalue. We want to study left-hand-side of this equation as a function of $\bc{\lambda}$, taking the values in $\bc{\A}$ as constants.
As we’ve seen, expanding the determinant into an explicit form can get a little hairy for dimensions larger than 3, but we don’t need to make it explicit, so long as we can tell what kind of function it is. To illustrate, say we have a $2 \times 2$ matrix
\[\bc \A = \begin{pmatrix}a & b \\ c & d\end{pmatrix} \p\]In that case, the value $\left |\,\bc{\A} - \bc{\lambda}\I\,\right|$ works out as
\[(a-\bc{\lambda})(d - \bc{\lambda}) - bc \p\]We can multiply out these brackets, and we would get a polynomial with $\bc{\lambda}$ as its variable. This polynomial would have $\bc{\lambda}^2$ as the highest power. The values for which this polynomial equal zero, its roots, are the eigenvalues of the original matrix $\bc{\A}$.
For a $n\times n$ matrix, as we saw, the determinant consists of one terms for each possible permutations of length n, each of which consists of $n$ elements of the matrix multiplied together. If any of these elements come from the diagonal, they contain $\bc{\lambda}$. That means each term contains at most $n$ $\bc{\lambda}$s, giving us an $n$-th order polynomial.
As you may have guessed, this function is what we call the characteristic polynomial of $\bc{\A}$. The points where this function is $0$, the roots of the polynomial, are the eigenvalues of $\bc{\A}$.
And this means that we can apply a whole new set of tools from the analysis of polynomials, to the study of eigenvectors. We never have to work out the characteristic polynomial explicitly, we can just use the knowledge that the determinant is a polynomial and use what we know about polynomials to help us further along towards the spectral theorem.
And one of the richest and most versatile tools to come out of the analysis of polynomials, is the idea of complex numbers.
Complex numbers
Complex numbers spring from the idea that there exists a number $i$ for which $i^2$ is $-1$. We don’t know of any such number, but we simply assume that it exists, and investigate the consequences. For many people this is the point where mathematics becomes too abstract and they tune out. The idea that squares can be negative clashes too much with our intuition for what squares are. The idea that we just pretend that they can be negative and keep going, seems almost perverse.
And yet, this approach is one that humanity has followed again and again in the study of numbers. If you step back a bit, you start to see that it is actually one of the most logical and uncontroversial things to do.
The study of numbers started somewhere before recorded history, in or before the late stone age, when early humans began counting things in earnest, and they learned to add. I have five apples, I steal three apples from you, now I have eight apples. That sort of thing.
At some point, these early humans will have solidified their concept of “numbers”. It is a set of concepts (whose meaning we understand intuitively) which starts $1, 2, 3, \ldots$ and continues. If you add one number to another, you always get another number. If the number was big, they may not have had a name for it, but a patient paleolithic human with enough time could certainly have carved the required number of tally marks into an animal bone.
The operation of addition can also be reversed. If $5 + 3$ gives $8$, then taking $5$ away from $8$ gives $3$. If I steal $5$ apples from your collection of $8$, you still have $3$ left. Thus, subtraction was born. But subtraction, the inverse of addition, required some care. Where adding two numbers always yielded a new number, subtracting two numbers doesn’t always yield a new number. You can’t have $5 - 8$ apples, because if you have $5$ apples I can’t steal more than $5$ of them.
As societies grew more complicated, financial systems developed and debt became an integral part of daily life. At some point, the following tought experiment was considered. What if $5-8$ is a number after all? We’ll just give it a name and see if it makes sense to compute with it. No doubt many people were outraged by such a suggestion, protesting that it was unnatural, and an insult to whatever God they believed had designed the numbers. But simple investigation showed that if these numbers were assumed to exist, they followed simple rules and, it made sense to think of them as a kind of mirror image of the natural numbers, extending to infinity in the opposite direction. $5 - 8$ was the mirror image of $3$, so it made sense to call it “$-3$”.
The skeptics might argue that this made no sense, because there is no such thing as having $-3$ apples, but the mathematicians will have countered that in other areas, such as finance, there were concepts that could be expressed very beautifully by the negative numbers. If I owe you $3$ apples, because of my earlier theft, and you steal 8 apples from me, I now owe you $-5$ apples, or rather you owe me $5$.
The same principle can be applied to multiplication. If your tribe has $8$ families, and every family is entitled to $5$ apples, you need to find $8 \times 5$ apples. Again, an operator, and any two numbers you care to multiply will give you a new number (even if you believe in negative numbers).
And again, you can do the opposite: if the harvest has yielded $48$ apples, you can work out that every family in your tribe gets $6$ of them. But again, you have to be careful about which numbers you apply the inverse to. Sometimes you get a known number, and sometimes you don’t. If you have 50 apples, suddenly there is no known number that is the result of $50/8$.
But what if there was? What if we just gave $50/8$ a name and started investigating? We’d find out pretty quickly that it would make sense to think of these numbers as lying in between the integers. We call these the rational numbers. Whoever it was that invented the rationals must have run into less resistance than the inventor of the negative numbers; it’s much easier to imagine half an apple than to imagine $-3$ of them.
The pattern is hopefully becoming clear. Let’s have one more example, to really drive the point home, and also to bring us far enough into recorded history so we can actually see how people dealt with these revelations. If adding is repeated counting, and multiplication is repeated adding, then raising to a power, repeated multiplication, is the next step in the hierarchy.
The story should be familiar at this point. Any two natural numbers $a$ and $b$ can be “exponentiated” together as $a^b$ and the result is another natural number.
The inverse operation is a b-th root, but we can stick with square roots to illustrate our point. In fact the square root of 2, the length of the diagonal of a unit square, is all we need. In this case, there is nothing abstract or perverse about the quantity $\sqrt 2$: it’s the distance from one corner to the opposite in a square room with sides of 1 meter.

And yet, when people investigated, it caused great upset.
The man who gave his name to the theorem we would use to work out the above picture, Pythagoras, was the head of a cult. A cult dedicated to mathematics. They lived ascetically, much like monks would, centuries later, and dedicated themselves to the study of nature in terms of mathematics. When asked what the purpose of man was, Pythagoras answered “to observe the heavens.” One fervent belief of the Pythagoreans was that number and geometry were inseperable: all geometric quantities could be expressed by (known) numbers.
The story of the Pythagoreans is a mathematical tragedy. It was one of their own, commonly identified as Hippasus of Metapontum, who showed that no rational number corresponded exactly to $\sqrt{2}$. Some aspects of geometry were outside the reach of the known numbers. According to legend, he was out at sea when he discovered this, and was promptly thrown overboard by the other Pythagoreans.
Of course, with the benefit of hindsight, we know how to manage such upsetting discoveries. We simply give the new number a name, “$\sqrt{2}$”, and see if there’s some place among the numbers where it makes sense to put it. In this case, somewhere between $141/100$ and $142/100$, in a space we can make infinitely small by choosing better and better rational approximations.
With this historical pattern clearly highlighted, the discovery of the complex numbers should be almost obvious. In fact, we don’t even need a new operation to invert, we are still looking at square roots, but instead of applying the square root to positive integers, we apply it to negative integers. To take the simplest example, we’ll look at $\sqrt{-1}$. No number we know gives $-1$ when we square it, so our first instinct is to dismiss the operation. The square root is only allowed for a subset of the real-valued numbers. Just like subraction was only allowed for a subest of the natural numbers, and division was only allowed for a subset of the integers.
But, what if the number $\sqrt{-1}$ did exist? What would the consequences be?
As the previous paragraphs should illustrate, this kind of investigation is usually born out of necessity. Like a fussy child given a new food, people are consistently reluctant to accept new types of numbers. In this case, what pushed us over the edge was the study of polynomials; functions of the form:
\[f(x) = \bc{a}x^3 + \bc{b}x^2 + \bc{c}x + \bc{d}\]where the highest exponent in the sum indicates the order of the polynomial.
The problem of finding the roots of a polynomial, the values of $x$ for which $f(x)$ is equal to $0$ crops up in all sorts of practical problems. In some cases, this leads to squares of negative numbers, as we see when we try to solve $x^2 + 1 = 0$. This didn’t worry anybody, of course, since this function lies entirely above the horizontal axis, so it’s only natural that solving for the roots leads to a contradiction.

However, when people started to work out general methods for finding the roots of third order polynomials, like $x^3 - 15x - 4$, which does have roots, it was found that the methods worked if one temporarily accepted $\sqrt{-1}$ as an intermediate value, which later canceled out. This is where the phrase imaginary number originates. People (Descartes, to be precise) were not ready to accept these as numbers, but no one could deny their utility.
Eventually, people followed the pattern that they had followed centuries before for the integers, the rationals and all their successors. We give the new number a name, $i = \sqrt{-1}$, and we see if there’s any way to relate it, geometrically, to the numbers we know.
Let’s start with addition. What happens if we add $i$ to some real number, say $3$? The simple answer is that nothing much happens. The most we can say about the new number is that it is $3 + i$.
Multiplication then. Again $2i$ doesn’t simplify in any meaningful way, so we’ll just call the new number $2i$. What if we combine the two? With a few subtleties, we can rely on the basic rules of algebra to let us multiply out brackets and add things together. So, if we start with $i$, add 3 and then multiply by 2, we get:
\[\begin{align} 2(i + 3) = 2\cdot3 + 2\cdot i = \bc{6} + \rc{2}i \end{align}\]Here is a very common result: we’ve applied a bunch of operations, involving the imaginary number $i$, and the result can be written as the combination of a real value $\bc{r}$, another real value $\rc{c}$ and $i$ as:
\[\bc{r} + \rc{c}i \p\]Let’s call any number that can be written in this way a complex number. The set of all complex numbers is written as $\mathbb C$. At this point you may be worried. What if we come up with another operation that is not defined for all complex numbers? Are we going to have to make another jump? Are we going to find ever bigger families of numbers to deal with? It turns out that in many ways, $\mathbb C$ is the end of the line. So long as we stick to algebraic operations, we can do whatever we like to complex numbers, and the result will always be well defined as another complex number.
To illustrate, let’s show this for a few simple examples. Lets say we have two complex numbers $\gc{a} + \gc{b}i$ and $\oc{c} + \oc{d}i$. If we add them, we get
\[(\gc{a} + \gc{b}i) + (\oc{c} + \oc{d}i) = \gc{a} + \oc{c} + \gc{b}i + \oc{d}i = \bc{(a + c)} + \rc{(b + d)}i\]If we multiply them, we get
\[\begin{align} (\gc{a} + \gc{b}i)(\oc{c} + \oc{d}i) &= \gc{a}\oc{c} + \gc{a}\oc{d}i + \gc{b}i\oc{c} + \gc{b}i\oc{d}i \\ &= (\gc{a}\oc{c} + \gc{b}\oc{d}\kc{i^2}) + (\gc{a}\oc{d} + \gc{b}\oc{c})i \\ &= \bc{(ac - bd)} + \rc{(ad + bc)}i \p \end{align}\]That is, one real-valued number, added to $i$ times another real-valued number. Note that in the second line, we can use $i^2 = -1$, because we know that $i = \sqrt{-1}$. In short, multiplying or adding any two complex numbers together gives us another complex number.
Because each complex number can be written as the combination of two real valued numbers, it makes sense to visualize them as lying in a plane. We plot the value of the real term along the horizontal axis and the value of the imaginary term along the vertical.

The real-valued numbers that we already knew are a subset of the complex numbers: those complex number for which the imaginary part is zero. In this picture, the real-valued numbers are on the horizontal axis.
Note that this is just a visualization. There is nothing inherently two-dimensional about the complex numbers, except that there is a very natural mapping from $\mathbb C$ to $\mathbb R^2$. At heart, it’s just a set of numbers with a bunch of operations defined for them.
The nice thing about the mapping to the plane, however, is that we can take operations like multiplication, addition and so on, and see what they look like in the plane. This way, we can build a very helpful visual intuition for how the complex numbers behave.
Let’s look at the most important concepts we’ll need going forward. For addition, we can build on our existing intuitions. Adding two complex numbers works the same as adding two vectors in the plane: we place the tail of one on the head of the other.

The same logic shows that subtraction of complex numbers behaves as you’d expect. To compute $x - y$, we subtract the real part of $x$ from the real part of $y$ and likewise for the imaginary part. Geometrically, this corresponds to vector subtraction in the plane.
To see what multiplication looks like, we can switch to a different way of representing complex numbers. Instead of giving the Cartesian coordinates $(\bc{r}, \rc{c})$ that lead to the number $z = \bc{r} + \rc{c}i$, we use the polar coordinates. We give an angle $\gc{a}$ from horizontal axis and a distance $\gc{m}$ from the origin. The angle is also called the phase and the distance is called the magnitude or the modulus. When we write a number like this, we’ll use the notation $z = \gc{m}\angle \gc{a}$. To refer to the magnitude of a complex number $z$, which we’ll be doing a lot, we use the notation $|z|$.

We call this representation of a complex number polar notation, and the earlier representation Cartesian notation.
The reason polar notation is so useful, is that multiplication looks very natural in it. To see the relation, assume that we have a number $z = \gc{m}\angle \gc{a}$. Then basic trigonometry tells us that in Cartesian notation, this number is written as $z = \bc{\gc{m}\co(\gc{a})} + \rc{\gc{m} \si(\gc{a})} i$. Let’s see what happens if we take two numbers, in polar notation, and multiply them:
$$\begin{align*} & (\gc{m} \angle \gc{a})(\oc{n} \angle \oc{b})& \\ &= (\gc{m}\co(\gc{a}) + \gc{m} \si(\gc{a}) i)(\oc{n}\co(\oc{b}) + \oc{n}\si(\oc{b}) i) \\ &= \gc{m}\co \gc{a} \;\oc{n} \co \oc{b} + \gc{m} \si \gc{a}\; \oc{n} \si \oc{b} + (\gc{m} \co \gc{a} \;\oc{n} \si \oc{b} + \oc{n}\co \oc{b}\; \gc{m} \si \gc{a})i \\ &= \gc{m}\oc{n} (\co \gc{a} \co \oc{b} - \si \gc{a} \si \oc{b}) + \gc{m}\oc{n} (\co \gc{a} \si \oc{b} + \co \oc{b} \si \gc{a})i \\ &= \gc{m}\oc{n} \co(\gc{a} + \oc{b}) + \gc{m}\oc{n} \si(\gc{a} + \oc{b})i \\ &= (\gc{m}\oc{n}) \angle (\gc{a}+ \oc{b}) \end{align*}$$
In the third line, we apply the multiplication in Cartesian notation that we already worked out earlier. Then, in the fifth line, we apply some basic trigonometric sum/difference identities.
What this tells us, is that when we view complex numbers in polar coordinates, multiplication has a very natural interpretation: the angle of the result is the sum of the two original angles, while the magnitude of the result is the product of the two original magnitudes.

The easiest way to define division is as the operation that cancels out multipliciation. For each $z$, there should be a $z^{-1}$ so that multiplying by $z$ and then by $z^{-1}$ brings you back to where you were. Put simply $zz^{-1} = 1$. Dividing by $z$ can then be defined as multiplying by $z^{-1}$. Using the polar notation, we can see that this definition of $z^{-1}$ does the trick:
\[z^{-1} = (\gc{m}\angle \gc{a})^{-1} = \frac{1}{\gc{m}}\angle -\gc{a} \p\]Note how this view of multiplication agrees with special cases that we already know. For real numbers, the angle is always $0$, and the magnitude is equal to the real value. Therefore, multiplying real numbers together reduces to the multiplication we already knew.
The number $i$ is written as $1\angle90\deg$ in polar coordinates. That means that multiplying a number $z$ by $i$ keeps the magnitude of $z$ the same, but rotates it by $90$ degrees counter-clockwise. A real number multiplied by $i$ is rotated from the horizontal to the vertical axis. If we multiply by $i$ twice, we rotate $180$ degrees, which for real numbers means negating them. This makes sense too, because $z \cdot i \cdot i = z i^2 = z \cdot -1$.
Which brings us to exponentiation. Raising complex numbers to arbitrary values, including to complex ones, is an important topic, but one which we can sidestep here. All we will need is the ability to raise a complex number to a natural number. That follows very naturally from multiplication:
\[(\gc{m} \angle \gc{a})^n = (\gc{m} \angle \gc{a})(\gc{m} \angle \gc{a}) \ldots (\gc{m} \angle \gc{a}) = \gc{m}^n \angle n\gc{a} \p\]Again, let’s look at some special cases. If the angle is $0$, we stay on the real number line, and the operation reduces to ordinary exponentiation. If the magnitude is $1$ but the angle is nonzero, then we just rotate about the origin over the unit circle in $n$ steps of angle $a$.

The main thing we need, however, is not integer exponentiation, but its inverse: the $n$-th root. Given some complex number $z = m\angle a$, which other number do we raise to the power $n$ so that we end up at $z$? The answer follows directly from our polar view of the complex plane: the magnitude should be $\sqrt[n]{m}$, which is just the real-valued $n$-th root, and the angle should be $a/n$.
Let’s check for $\sqrt{-1}$, which started all this business. Which number should we raise to the power 2, so that we get $-1$? The magnitude of $-1$ is $1$, so our number has magnitude $\sqrt{1} = 1$. Now we need a number with magnitude one, so that twice its angle equals $180 \deg$. This is a $90\deg$ angle, so our number is $1\angle 90\deg$, which is exactly where we find $i$.
Notice how this solves the problem we had when we were constrained to the real line. Then we had negative numbers to deal with, and the real $n$-th root does not exist for negative numbers. Now, we are only ever applying the $n$-th root to magnitudes, which are positive. The rest is dealt with by rotating away from the real numbers. This means that when it comes to complex numbers, we can always find some number that, when raised to $n$ gives us $z$. We call this the complex $n$-th root $\sqrt[n]{z}$.
Note however, that this is not always a unique number. Let’s say we raise $1\angle 10\deg$ to the power of $4$. This gives us $1\angle 40\deg$, so $1\angle 10\deg$ is a fourth root of $1\angle 40\deg$. However, if we raise $1\angle 92.5\deg$ to the power of $4$, we get $1\angle 370\deg$, which is equal to $1\angle 10\deg$ as well. Any angle $a’$ for which $a’\frac{1}{n}\,\text{mod}\;360 = a$ will give us an $n$-th root of $m\angle a$.
How many solutions does this give us for any given number? It’s easiest to visualize this if we plot the $n$-th roots of 1.

For each, of course, the real value $1$ is a solution, but for the higher powers, there are additional solutions on the unit circle. For $\sqrt{1}$, for instance, multiplying $-1$ by itself rotates it buy 180 degrees to coincide with $1$. For $\sqrt[3]{1}$, we get three roots, two of which non-real. The solution with angle $120\deg$, when raised to the power of $3$ gives us an angle of $360\deg = 0\deg$. The solution with angle $240\deg$ puts the angle after cubing at $720 \deg = 0 \deg$.
In short, every multiple of $360$: $0$, $360$, $720$, $1080$, $\ldots$, can be divided by $n$ to give us a solution. Once we get to $360n$, dividing by $n$ gets us back to a solution we’ve already seen, so we get $n$ unique solutions in total.
To translate this to roots of any complex number $m\angle a$, we simply scale the circle so that its radius is $\sqrt[n]{m}$ and then rotate it so that the first solution points in the direction of $a/n$.

The fundamental theorem of algebra
The reason we are bringing in complex numbers, is that we are interested in talking, in general terms, about the roots of the chracteristic polynomial. When all we have access to are real-valued numbers, this becomes a messy and unpredictable business. A polynomial of order $n$ can have anywhere between no and $n$ roots. When we add complex numbers to our toolbelt, the whole picture becomes a lot simpler. And that is down to a result called the fundamental theorem of algebra.
The theorem has many equivalent statements, but this is the one most directly relevant to our purposes.
Any non-constant polynomial of order $n$ has exactly $n$ complex roots, counting multiplicities.
To prove this, the first thing we need is to show that each such polynomial has one root. After that, the rest is straightforward. So straightforward (to some) that this is often seen as an alternative statement of the fundamental theorem:
Any non-constant polynomial of order $n$ has at least one complex root.
Let \(p(z) =\bc{c_n}z^n + \ldots + \bc{c_1}z + \bc{c_0}\) be our polynomial. For our purposes, we can think of the coefficients as real-valued, but the theorem holds for complex coefficients as well.
To find a root of $p$, we will consider the function $ |p(z)| $. That is, the magnitude of the complex number that we get out of $p$. This provides the following benefits:
- The magnitude is always non-negative. That means that the lowest possible value that $|p(z)|$ can take on is $0$, at which point we must have $p(z) = 0$. In short, for a root of $p(z)$, $|p(z)|$ is both $0$ and at a minimum.
- Since the magnitude of a complex number is a single real value, $|p(x)|$ is a function from two dimensions (the complex plane) to one dimension (the reals) and we can easily visualize it in three dimensions. This is not so easy for $p(x)$ itself, since we have a two-dimensional input and a two-dimensional output.
Our big shortcut in this proof will be to look at what the magnitude does in extreme cases: for very large inputs, and for inputs very close to the minimum. We will see that in both cases, the function can be approximated well by the magnitude of a simple polynomial.
To see this, let’s start with a simple real-valued example. The polynomial $p(x) = \rc{x^3} + \bc{x^2} + \gc{x}$ in the positive range. In this area, $p(x)$ is equal to its magnitude, so we don’t need to worry about the distinction yet.

What we see here, is that as $x$ gets bigger, the term $\rc{x^3}$ dominates. Almost all the contribution to the magnitude comes from this term, and pretty soon, the simpler polynomial $\rc{x^3}$ becomes a pretty good approximation of the polynomial $\rc{x^3} + \oc{x^2} + \bc{x}$. This is not surprising, since the cube grows much faster than the square which grows much faster than the identity.
Toward $x=0$, where $p$ has a minimum, the opposite happens. As $\rc{x^3}$ grows the fastest when $x > 1$, so it shrinks the fastest when $0 < x < 1$. In this regime the term that shrinks the slowest, $\bc{x}$ begins to dominate, and $\bc{x}$ becomes a good approximation of the function.
Of course, this is just one polynomial. If we move to complex polynomials, and we allow for any order and all possible coefficients, does this pattern still hold? Let’s imagine a generic complex polynomial. In this case, all terms in the polynomial are complex numbers, and the value of the polynomial is their sum.

The magnitude $|p(z)|$ of the polynomial at $z$ is the distance of the end result to the origin. Each term contributes to this magnitude in a different direction. If we want to show that a particular term dominates, we can look at the worst case: that term points in one direction, and all other terms point in the exact opposite direction.

In this case, we can ignore the angles of the terms and focus only on their magnitudes. If we assume the highest-order term points in the opposite direction of the rest, the total magnitude is
$$\begin{align*} |p(z)| &= \left |\bc{c_{n}} {z}^n\right| - \left|\bc{c_{n-1}} {z}^{n-1}\right | - \ldots - \left |\bc{c_{1}} z\right | - \left |\bc{c_{0}}\right| \\ & = |\bc{c_{n}}| {|z|}^n - |\bc{c_{n-1}}| {|z|}^{n-1} - \ldots - |\bc{c_{1}}| |z| - |\bc{c_{0}}| \end{align*}$$
We will first use this to show that $|p(z)|$ has some definite minimum. One alternative would be if $p(z)$ is a function that is positive everywhere and monotonically increasing in some direction, like $e^x$ is on the real number line. We'll need to exclude such possibilities first.
Assume that $|z| > 1$. If so, we make the total value of the sum smaller if we repace all lower-order powers by $z^{n-1}$. This means that
$$\begin{align*} |p(z)| &> |\bc{c_{n}}| {|z|}^n - \sum_{i\in 1..n-1} |\bc{c_{i}}| {|z|}^{n-1} - |\bc{c_{0}}|\\ &= |\bc{c_{n}}| {|z|}^n - {|z|}^{n-1}\sum_{i\in 1..n-1} |\bc{c_{i}}| - |\bc{c_{0}}| \\ &= {|z|}^{n-1} \left (|\bc{c_n}| {|z|} - \sum_{i\in 1..n-1} |\bc{c_{i}}|\right) - |\bc{c_0}| \end{align*}$$
If we choose $z$ so that its magnitude is larger than $\frac{1}{|\bc{c_n}|} \sum_i |\bc{c_i}|$, the factor in brackets becomes positive. Beyond that, we know that there is some value of $|z|$ large enough that the first term is bigger than the second. In short, for a suffciently large $B$, we can always choose a value of $z$ such that $|p(z)|$ is larger than $B$.
This means we can draw some large circle with radius $R$, find the smallest value of $|p(z)|$ inside the circle, and then draw a second circle with radius $B$ so that all values outside of $p(z)$ outside the second circle are larger than this minimum inside the first circle. This means $|p(x)|$ has a definite minimum inside the second circle.
Now, all we need to do is show that this minimum can be expressed by a complex number. To do that, we'll follow the same sort of argument, but with the magnitude going to $0$, so that the lower-order terms dominate.
First, let $z_0$ be the minimum we've just shown must exist. Translate $p$ so that this minimum coincides with the origin, and call the result $q(z)$. Specifically, $q(z) = p(z + z_0)$.
This is another $n$-th order polynomial. We'll call its coefficients $\bc{d_i}$. Note that $q(0)$ has the same value as $p(z_0)$ by construction. What we want to show is that $p(z_0) = 0$.
In many polynomials the lowest-order term is the first-order term $\bc{c_1}z$. However, we need to account for cases where this term is always zero. To be general, we write $q$ as
$$ q(z) = \bc{d_0} + \bc{d_k}z^k + \bc{d_{k+1}}z^{k+1} + \;\ldots\; + \bc{d_n}z^n $$
Where $k$ is the order of the lowest-order, non-constant term.
We’ll show that the proportion of the sum contributed by the higher order terms vanishes as we get near zero, so we can take the simpler function $q’(z) = \bc{d_0} + \bc{d_k}z^k$ as a good approximation, that becomes perfect at the origin (note that $q(0) = q’(0)$).
More formally, lets look at the ratio between the higher-order terms and the $k$th-order term:
$$ r = \frac{ |\bc{d_{k+1}}||z|^{k+1} + \;\ldots\; + |\bc{d_n}||z|^n }{ |\bc{d_{k}}||z|^k } \p $$
Assuming that $|z| < 1$, the numerator is made bigger by reducing all exponents to $z^{k+1}$, so
$$ r < \frac{ |z|^{k+1} \sum_{i\in k+1..n} |\bc{d_i}| }{ |\bc{d_{k}}||z|^k } = |z|\frac{ \sum_{i} |\bc{d_i}| }{ |\bc{d_{k}}| } \p $$
The second factor is a constant, so if we want to make the contribution of the higher order terms less than some given $\epsilon$, we just need to choose a $z$ with small enough magnitude.
This allows us to continue our analysis with $q'$ instead of $q$. Next, we can show that because $|q'(z)|$ has a minimum at $0$, that minimum must be equal to $0$, so that $\bc{d_0} = 0$.
At first, this may not be obvious. Why should a function $q'(z) = \bc{c_k}z^k + \bc{c_0}$ necessarily have $\bc{c_0} = 0$ if its magnitude has a minimum at $0$? It becomes clearer if we take the image of the roots of $z^n - 1$ that we showed earlier, and create a 3d plot of the corresponding magnitude functions $|z^n - 1|$.
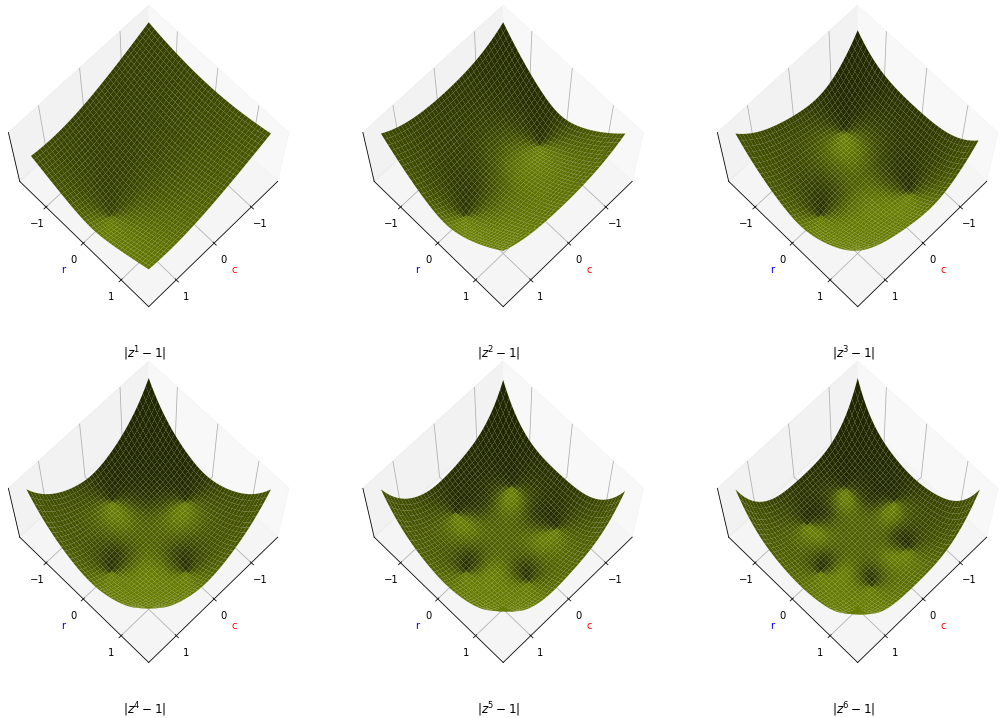
This kind of picture applies to the more general function $|\bc{c_k}z^k + \bc{c_0}|$ as well: the two constants rotate the image and change how close the roots are to the origin, but unless $\bc{c_0} = 0$, we get a ring of roots some distance from the origin and no root at the origin. This contradicts what we know: that $|q(z)|$ has a minimum at 0, so we know that $c_0$ must be $0$.
To prove this formally, let $z = \sqrt[k]{-\bc{d_0}/\bc{d_k}}$, one of the roots of $q'$ , and let $\epsilon$ be some real value near 0. Then we have:
\[\begin{align*} |q'(\epsilon z)| &= |\bc{d_0} + \bc{d_k} \cdot - \epsilon^k \frac{\bc{d_0}}{\bc{d_k}}| \\ &= |\bc{d_0} - \epsilon^k \bc{d_0}| \end{align*}\]Note that both terms in this last line point in the same direction, so if $\bc{d_0} >0$, the resulting magnitude is smaller than $|\bc{d_0}|$, which contradicts what we already know: that $|\bc{d_0}|$ is the minimum of $q'$. Therefore $\bc{d_0} = 0$, $q(0)$ is a root of $q$ and $p(z_0)$ is a root of $p$.
From one root to n roots
Now that we know that each polynomial has at least one root, how do we get to multiple roots? In high school, we learned that when we were faced with a (real valued) second-degree polynomial to solve, sometimes, if we were lucky, we could find its factors. For instance, the function:
\[f(x) = x^2 - \bc{3}x + \bc{2}\]can be rewritten as
\[f(x) = (x - 1)(x - 2) \p\]Now, the function is expressed as a multiplication of two factors, and we can deduce that if $x$ is equal to $1$ or to $2$, then one of the factors is $0$, so the whole multiplication is zero. Put simply, if we can factorize our polynomial into factors of the form $x - r$, called linear factors, then we know that the $r$’s are its roots.
This is how we’ll show that any $p(z)$ of degree $n$ has $n$ complex roots: we’ll factorize it into $n$ factors of the form $z - r$, where we will allow $r$ to be complex.
To allow us to factor any polynomial into linear factors, we’ll use a technique called Euclidian division, which allows us to break up polynomials into factors. The general method works for any polynomial factor, but we can keep things simple by sticking to one specific setting
Given a polynomial $p(z)$ of degree $n$ and a linear factor $z - r$, there is a polynomial $q(z)$ of degree $n-1$ and a constant $\rc{d}$, called the remainder such that $$p(z) = (z-r)\bc{q(z)} + \rc{d} \p$$
Now, let $r$ be a root of $p(z)$—we know there must be one—and apply the Euclidian division so that we get \(p(z) = (z-r)\bc{q(z)} + \rc{d} \p\)
Since $r$ is a root, $p(r)$ must be zero. The first term is zero because of the factor $(z-r)$, so $\rc{d}$ must be zero as well. In short, if we apply Euclidean division with a root $r$, we get
\[p(z) = (z-r)\bc{q(z)} \p\]And with that, we can just keep applying Euclidean division to $\bc{q(z)}$. Each time we do this, we get one more factor, and the degree of $\bc{q(x)}$ is reduced by one.
This tells us what we were looking for: every polynomial $p(z)$ of degree $n$ can be decomposed into a product of $n$ linear terms
\[p(z) = (x - r_1)(x - r_2) \ldots(x-r_n)\]so it must have $n$ roots.
What we haven’t proved yet, is whether all of these roots are distinct. And indeed, it turns out they need not be. We can factor any $p(z)$ into $n$ linear factors, but it may be the case that some of them are the same. For instance,
\[p(z) = z^2 -6z + 9 = (z - 3)(z - 3)\]We call these multiplicities. If we count every root by the number of factors it occurs in, then the total comes to $n$.
We’ll call a root a real if it is a real number and complex otherwise. Given the $n$ roots of a particular polynomial, what can we say about how many of them are real and how many of them are complex?
We can have a polynomial with all roots complex and one with all roots real, or something in between, but there is a constraint: if our polynomial has only real-valued coefficients, then complex roots always come in pairs. This is because if a complex number $\bc{r} + \rc{c}i$ is a root of $p(z)$, then that same number with the complex part subtracted, $\bc{r} - \rc{c}i$, is also a root of $p(z)$.
The second number is called the conjugate of the first. We denote this with a vertical bar: $\overline{z}$ is the conjugate of $z$. Visually, the conjugate is just the reflection image in the real number line.
Why is it the case that if $z$ is a root that $\overline{z}$ is a root too? Well, it turns out that taking the conjugate distributes over many operations. For our purposes, we can easily show that it distributes over addition and multiplication and that it commutes over integer powers.
\[\begin{align*} \overline{\gc{z}+\oc{w}} = \overline{\gc{z}} + \overline{\oc{w}} &\hspace{1cm} \overline{\gc{a} + \gc{b}i + \oc{c} + \oc{d}i} = \gc{a} + \oc{c} - (\gc{b}+\oc{d})i = \gc{a} - \gc{b}i +\oc{c} - \oc{d}i = \overline{\gc{a} + \gc{b}i} + \overline{\oc{c} + \oc{d}i} \\ \overline{\gc{z}\oc{w}} = \overline{\gc{z}}\;\overline{\oc{w}} &\hspace{1cm} \overline{\gc{m}\angle\gc{a} \cdot \oc{n}\angle \oc{b}} = \overline{\gc{m}\oc{n}\angle(\gc{a} + \oc{b})} = \gc{m}\oc{n}\angle(- \gc{a} - \oc{b}) = \gc{m}\angle-\gc{a} \cdot \oc{n}\angle-\oc{b} = \overline{\gc{m}\angle \gc{a}} \cdot \overline{\oc{n}\angle \oc{b}}\\ \overline{\gc{z}^n} = {\overline{\gc{z}}}^n &\hspace{1cm} \overline{(\gc{m}\angle \gc{a})^n} = \overline{\gc{m}^n \angle n\gc{a}} = \gc{m}^n \angle - n\gc{a} = (\gc{m} \angle - \gc{a})^n = \overline{\gc{m}\angle \gc{a}}^n \end{align*}\]If $p(z) = 0$, then $\overline{p(z)} = 0$ too, since $0$ is a real value, so it’s equal to its own conjugate. For the roots of a polynomial $p$, this gives us:
\[\begin{align*} 0 &= \overline{ p(z)} \\ &= \overline{\bc{c_n}z^n + \ldots + \bc{c_1}z + \bc{c_0}} \\ &= \bc{c_n}\overline{z}^n + \ldots + \bc{c_1}\overline{z} + \bc{c_0} \\ &= p(\overline{z})\p \end{align*}\]In short, if a complex number is a root of $p(z)$, then its conjugate is too. This means that if we have a 2nd degree polynomial (with real coefficients), we can have two real roots, or one pair of complex roots. What we can’t have is only one real root, since then the other would be complex by itself, and complex roots have to come in pairs.
Similarly, if we have a 3rd degree polynomial, we must have at least one real root, since all complex roots together must make an even number.
This should make sense if you think about the way real valued polynomials behave at their extremes. A 2nd degree polynomial either moves off to positive or to negative infinity in both directions. That means it potentially never crosses the $x$ axis, resulting in two complex roots, or it does cross the $x$ axis, resulting in two real roots. If it touches rather than crosses the $x$ axis, we get a multiplicity: a single real-valued root that occurs twice.

A 3rd degree polynomial always moves off to negative infinity in one direction, and positive infinity in the other. Somewhere in between, it has to cross the $x$ axis, so we get one real-valued root at least. The rest of the curve can take on a single bowl shape, so the remaining two roots can be both real, when this bowl crosses the horizontal axis, or complex when it doesn’t.
Back to eigenvalues
This was a long detour, so let’s restate what brought us here. We were interested in learning more about the eigenvalues of some square matrix $\bc{\A}$. These eigenvalues, as we saw, could be expressed as the solutions $\bc \lambda$ to the following equation
\[\left|\;\bc{\A} - \bc{\lambda}\I\;\right| = 0 \p\]We found that the determinant on the left is a polynomial in $\bc \lambda$, so we can use what we’ve learned about polynomials on this problem: if we allow for complex roots, then we know that the characteristic polynomial of $\bc{\A}$ has exactly $n$ complex roots, counting multiplicities. The entries of $\bc{\A}$ are real values, so the polynomial has real coefficients, and the complex roots must come in pairs.
In the last part, we said that a given square matrix had between $0$ and $n$ eigenvalues. Now, we can refine that by allowing complex eigenvalues. An $n \times n$ matrix always has $n$ eigenvalues, counting multiplicities, some of which may be complex, in which case, they come in pairs. Let’s see what all these concepts mean in the domain of matrices and vectors.
First, lets look at a simple rotation matrix:
\[\bc{\R} = \begin{pmatrix}0 & -1 \\ 1 & 0\end{pmatrix} \p\]This matrix rotates points by 90 degrees counter-clockwise around the origin. All non-zero vectors change direction under this transformation, so previously, we would have said that $\bc{\R}$ has no eigenvalues. Now, let’s look at the roots of its characteristic polynomial:
\[\begin{align*} \left |\;\bc{\R} - \bc{\lambda}\I \;\right| &= \left |\begin{array} ~-\bc{\lambda} & -1 \\ 1 & -\bc{\lambda} \end{array}\right| \\ &= (-\bc{\lambda})(-\bc{\lambda}) - (-1)(1) \\ &= \bc{\lambda}^2 + 1 = 0 \end{align*}\]As expected, a polynomial with complex roots. In fact, a classic. Its roots are $i$, and its conjugate $-i$.
What does this mean for the eigenvectors? Remember that an eigenvector is the vector that doesn’t change direction when multiplied by the matrix. There are no such vectors containing real values, but if we allow vectors filled with complex numbers, there are.
This can get a little confusing: a vector in $\mR^2$ is a list of two real numbers. A vector in ${\mathbb C}^2$ is a list of two complex numbers. For instance:
\[\x = \begin{pmatrix} \bc{2} \;+ \rc{3}i \\ \bc{1} \;- \rc{2}i\end{pmatrix} \p\]The confusion usually stems from the fact that we’ve been imagining complex numbers as 2-vectors, so now we are in danger of confusing the two. Just remember, a complex number is a single value. It just so happens there are ways to represent it by two real values, which can help with our intuition. When we start thinking about complex matrices and vectors, however, it may hurt our intuition, so its best to think of complex numbers as just that: single numbers. Complex matrices and vectors are just the same thing we know already but with their elements taken from $\mC$ instead of $\mR$.
Linear algebra with complex matrices and vectors is a very useful field with many applications, but here, we will only need the basics. Addition and multiplication are well-defined for complex numbers, and all basic operations of linear algebra are simply repeated multiplication and/or addition. If we write things down symbolically, they usually look exactly the same as in the real-valued case.
For instance, if $\x$ and $\y$ are two complex vectors, then
$$ \begin{pmatrix} x_1 \\ x_2 \\ \vdots\\ x_n \end{pmatrix} + \begin{pmatrix} y_1 \\ y_2 \\ \vdots\\ y_n \end{pmatrix} = \begin{pmatrix} x_1 +y_1 \\ x_2 +y_2\\ \vdots \\ x_n +y_n\end{pmatrix} $$
where $x_i + y_i$ represents complex addition as we defined it before. Similarly, for a complex number $z$ and a complex vector $\x$:
$$ z\x = \begin{pmatrix} zx_1 \\ zx_2 \\ \vdots\\ zx_n \end{pmatrix} \p $$
Matrix multiplication also works the same as it does in the real-valued case: the result of multiplying a complex matrix $\A$ with complex matrix $\B$ is the matrix $\C$ where $C_{ij}$ is the sum-product of the elements of row $i$ in $\A$ and column $j$ in $\B$: $\sum_\rc{k}{A}_{i\rc{k}}{B}_{\rc{k}j}$.
In the real-valued case we would describe such a sum-product as the dot product or inner product of two vectors. But this is where we have to be careful in the complex world. The definition of the inner product takes a little bit of care.
The problem is that if we define the inner product of vectors $\x$ and $\y$ as $\x^T\y$, as we do in the real-valued case, it doesn’t behave quite as we want to. Specifically, when we take the inner product of a vector with itself, it doesn’t give us a well-behaved norm. A norm is (roughly) an indication of the length of the vector, and one important property is that there is only one vector that should have norm $0$, which is the zero vector.
However, a complex vector like:
\[\x = \begin{pmatrix}i \\ 1\end{pmatrix}\]will also lead to $\x^T\x = 0$. The problem is in the transpose. When we move from the real-valued to the complex-valued world, it turns out that simply transposing a matrix doesn’t always behave analogously to how it did before. For things to keep behaving as we expect them to, we need to replace the transpose with the conjugate transpose.
The conjugate transpose is a very simple operation: to take the conjugate transpose of a complex matrix, we simply replace all its elements by their conjugates, and then transpose it. If we write the conjugation of a matrix with an overline as we do in the scalar case, and the conjugate transpose with a $*$, then we define:
\[\A^* = \overline{\A}^T\]This may seem like a fairly arbitrary thing to do. Why should this particular operation be so fundamental in the complex world? To get some motivation for this, we can look at one more representation of complex numbers: as matrices.
Let $\bc{r} + \rc{c}i$ be a complex number. We can then arrange the two components in a $2 \times 2$ matrix as follows:
\[\begin{pmatrix} \bc{r} & -\rc{c} \\ \rc{c} & \bc{r} \\ \end{pmatrix}\]This is a single complex number represented as a real-valued matrix. The benefit of this representation is that if we matrix-multiply the complex numbers $x$ and $y$ in their matrix representations, it is equivalent to multiplying the two complex numbers together: the result is another $2 \times 2$ matrix representing the result of the multiplication $xy$ as a matrix.
\[\begin{array} ~ & \begin{pmatrix} \oc{c} & ~\;\;\;\;\;\;\;\;\;\;-\oc{d} \\ \oc{d} & ~\;\;\;\;\;\;\;\;\;\;\oc{c} \\ \end{pmatrix} \\ \begin{pmatrix} \gc{a} & -\gc{b} \\ \gc{b} & \gc{a} \\ \end{pmatrix} & \begin{pmatrix} \gc{a}\oc{c} - \gc{b}\oc{d} & - \gc{a}\oc{d} - \gc{b}\oc{c} \\ \gc{a}\oc{d} + \gc{b}\oc{c} & \gc{a}\oc{c} - \gc{b}\oc{d} \\ \end{pmatrix} \end{array}\]With this perspective in hand, we can also rewrite complex matrix multiplication. Start with a normal multiplication of a complex matrix $\A$ by a complex matrix $\B$. Now replace each element $A_{ij}$ in both with a $2 \times 2$ matrix of real values, representing the complex number $A_{ij}$ as described above. Then, concatenate these back into a matrix $\A^R$, which is twice as tall and twice as wide as $\A$, and filled with only real values. Do the same for $\B$.
Multiplying $\A^R$ and $\B^R$ together performs exactly the same operation as multiplying $\A$ and $\B$ together, except that the result is also in this $2 \times 2$ representation. This way, we can transform a complex matrix multiplication into a real-valued matrix multiplication.
It also shows the motivation for the complex conjugate. Compare the number $\bc{r} + \rc{c}i$ in a $2 \times 2$ representation to its conjugate $\bc{r} - \rc{c}i$:
\[\begin{pmatrix} \bc{r} & -\rc{c} \\ \rc{c} & \bc{r} \\ \end{pmatrix} \;\;\; \begin{pmatrix} \bc{r} & \rc{c} \\ -\rc{c} & \bc{r} \\ \end{pmatrix} \p\]They are transposes of each other. That means that if we take a complex matrix like $\A$, transform it to $2 \times 2$ representation $\A^R$ and then transpose it, the result ${\A^R}^T$ interpreted as a $2 \times 2$ representation of a complex matrix, is not the transpose of $\A$, but the conjugate transpose.
The conjugate transpose will be important for what’s coming up, so let’s look at a few of its properties.
First, note that if $\A$ contains only real values, the conjugate transpose reduces to the regular transpose: real values are unchanged by conjugation, so the conjugation step doesn’t change $\A$ and only the transpose remains.
Second, note that the conjugate transpose distributes over multiplication the same way the transpose does: $(\A\B)^* = \B^*\A^*$. This is because the conjugation distributes over the sums and multiplications inside the matrix multiplication so that we get: $\overline{\A\B} = \overline{\A}\,\overline{\B}$.
With the conjugate transpose, we can also define a dot product that will give us a proper norm. By analogy with the real-valued dot product written as $\x^T\y$, we define the dot product of complex vectors $\x$ and $\y$ as
$$ \x \cdot \y = \y^*\x = \sum_i x_i\overline{y_i} \p $$
Note that this is not a symmetric function anymore: it matters for which vector we take the conjugate transpose. By convention, it’s the second argument of the dot product.
This suggests a natural norm for complex vectors. In the real-valued case, the norm is the square of the vector's dot product with itself: $|\x| = \sqrt{\x\cdot\x}$. The same holds here.
This is a little more abstract and hard to visualize than the dot product in the real-valued case. We’ll just have to accept for now that the math works out. We’ll need to carry over the following properties of norms and dot products from the real-valued case:
- A vector with norm 1 is called a unit vector.
- Two vectors whose dot product is $0$ are called orthogonal. In this case it doesn't matter in which order we take the dot product: if it's zero one way around, it's also zero the other way around. This is easiest to see in the $2\times 2$ representation of the dot product.
- A matrix $\rc{\U}$ whose column vectors are all unit vectors, and all mutually orthogonal is called unitary. This is the complex analogue of the orthonormal matrix we introducted in part 2. Just like we had $\rc{\U}^T\rc{\U} = \I$ and $\rc{\U}^{-1} = \rc{\U}^T$ for orthonormal matrices, we have $\rc{\U}^*\rc{\U} = \I$ and $\rc{\U}^{-1} = \rc{\U}^*$ for unitary matrices.
- The standard basis for $\mR^n$, the columns of $\I$, serves as a basis for $\mC^n$ as well. For $\I$ to be a basis, we should be able to construct any complex vector $\z$ as a linear combination of the basis vectors. Here we can simply say $\z = z_1 \e_1 + \ldots + z_n \e_n$, where $\e_i$ are the columns of $\I$.
With these properties in place, we can return to the question of eigenvalues and eigenvectors.
Let’s go back to our example. Here is the operation of our rotation matrix:
$$ \begin{array} \times& \begin{pmatrix}z_1\\z_2\end{pmatrix} \\ \begin{pmatrix} 0 & -1 \\ 1 & 0 \end{pmatrix} & \begin{pmatrix}- z_2\\z_1\end{pmatrix} \end{array}\p $$
An eigenvector of this matrix is one for which this operation is the same as multiplying by the eigenvalue $i$ (or $-i$):
$$ \begin{align*} z_1i &= -z_2 \\ z_2i &= z_1 \\ \end{align*}\p $$
Remember that $z_1$ and $z_2$ are both complex numbers. We know already that on individual complex numbers, multiplying by $i$ has the effect of rotating in the complex plane by 90 degrees counter-clockwise. That means that we're looking for a pair of complex numbers, such that rotating them this way turns the first into the negative of the of the second and the second into the first. This is true for any complex numbers of equal magnitude with a 90 degree angle between its two elements. For instance
\[\begin{pmatrix} 1 \\ i\end{pmatrix}\]is an eigenvector.
In the real-valued case, a given eigenvector could be multiplied by a scalar and it would still be an eigenvector. The same is true here as well. If we multiply the eigenvector above by a complex scalar $s = m\angle a$, this multiplication rotates both complex numbers in the vector above by the same angle $a$, so the angle between them stays 90 degrees.
This allows us to scale the eigenvector so that its norm becomes 1, giving us a unit eigenvector.
The spectral theorem
We are finally ready to begin our attack on the spectral theorem. The structure of the proof is as follows. We will first define a slightly different decomposition of a matrix, called the Schur decomposition.
We first show that any square matrix, complex or real, can be Schur-decomposed. Then, we show that the Schur decomposition of a symmetric real-valued matrix coincides with the eigendecomposition.
The Schur decomposition
Let $\bc{\A}$ be any complex-valued, $n \times n$ matrix. The Schur decomposition rewrites $\bc{\A}$ as the following product: $\bc{\A} = \rc{\U}^*\T\rc{\U}$, where $\rc{\U}$ is a unitary matrix, and $\bc{\T}$ is an upper triangular matrix (i.e. a matrix with non-zero values only on or above the diagonal). Compare this to the eigendecomposition $\bc{\A} = \rc{\P}^T\bc{\D}\rc{\P}$, where $\rc{\P}$ is orthogonal, and $\bc{\D}$ is diagonal.
Unlike the eigendecomposition, however, we can show that the Schur decomposition exists for any square matrix.
Proof. We will prove this by induction.
Base case. First, assume $n=1$. That is, let $\bc{\A}$ be a $1 \times 1$ matrix with value $\bc{a}$. Then, the Schur decomposition reduces to simple scalar multiplication with $\bc{\A} = \begin{pmatrix}u\end{pmatrix}^*\begin{pmatrix}\bc{a}\end{pmatrix}\begin{pmatrix}u\end{pmatrix}= \begin{pmatrix}u\bc{a}u\end{pmatrix}$, which is true for $u=1$ and $\bc{a} = \bc{A}_{11}$.
Induction step. Now we assume that the theorem holds for $n-1$, from which we will prove that it also holds for $n$.
We know that $\bc{\A}$ has $n$ eigenvalues, counting multiplicities and allowing complex values. Let $\bc{\lambda}$ be one of these, and let $\rc{\u}$ be a corresponding unit eigenvector.
Let $\rc{\W}$ be a matrix with $\u$ as its first column, and the remainder unit vectors orthogonal to $\rc{\u}$ and to each other. This makes $\rc{\W}$ a unitary matrix.
Now consider the matrix $\rc{\W}^{*}\bc{\A}\rc{\W}$. As illustrated below, the first column of $\bc{\A}\rc{\W}$ is $\bc{\A}\rc{\u}$, which is equal to $\bc{\lambda}\rc{\u}$ since $\rc{\u}$ is an eigenvector. This means that $(\rc{\W}^*\bc{\A}\rc{\W})_{11}$ is equal to $\rc{\u}^*\bc{\lambda}\rc{\u} = \bc{\lambda}$. The other elements in the first column are equal to the dot product of a scaled $\rc{\u}$ and another column of $\rc{\W}$. Since the columns of $\rc{\W}$ are mutually orthogonal, these are all $0$.

Call this matrix $\R$ (note that it is not triangular yet). So far we have shown that $\rc{\W}^{*}\bc{\A}\rc{\W} = \R$, or if we multiply both sides by $\rc{\W}^{*}$ and $\rc{\W}$, that $\bc{\A} = \rc{\W}\R\rc{\W}^*$.
Call $\R$'s bottom-right block $\bc{\A}'$ as indicated in the image. $\bc{\A}'$ is an $n-1 \times n-1$ matrix, so by the assumption made above, it can be factorized: $\bc{\A}' = \rc{\V}\bc{\Q}\rc{\V}^*$, with $\rc{\V}$ unitary and $\bc{\Q}$ upper triangular.
Now note that if we extend the matrix $\rc{\V}$ to an $n \times n$ matrix as follows
$$ \rc{\V}' = \begin{pmatrix} ~1 & 0 \ldots 0 \\ \begin{array} ~0\\ \vdots \\ 0 \end{array} & \rc{\V} \end{pmatrix} $$we can move it out of the submatrix $\bc{\A}'$, so that
$$\bc{\A} = \rc{\W}\rc{\V}'\begin{pmatrix} ~\bc{\lambda} & *\;\ldots\; * \\ \begin{array} ~0\\ \vdots \\ 0 \end{array} & \Q \end{pmatrix}\rc{\V}'^*\rc{\W}^*$$with the $*$'s representing arbitrary values.
We call the matrix in the middle $\bc{\T}$. Note that this is now upper triangular. Note also that $\rc{\V}'$ is unitary, since the column we added is a unit vector, and it's orthogonal to all other columns. Let $\rc{\U} = \rc{\W}\rc{\V}'$. Since $\rc{\W}$ and $\rc{\V}'$ are unitary, their product is as well, and with that we have
$$ \bc{\A} = \rc{\U}\bc{\T}\rc{\U}^* $$proving the theorem.
The important thing about the Schur decomposition is that it always works. No matter what kind of matrix we feed it, real or complex valued, with or without real eigenvalues, symmetric or asymmetric, singular or invertible, we always get a Schur decomposition out of it.
With this result in hand, the main difficulty of proving the spectral theorem is solved. We simply need to look at how the Schur decomposition behaves if we feed it a real-valued symmetric matrix
Proof of the spectral theorem
The spectral theorem
A matrix is orthogonally diagonalizable if and only if it is symmetric.
Proof. We will prove the two directions separately.
(1) If a real-valued matrix $\bc{\A}$ is orth. diagonalizable, it must be symmetric. Note that in an orthogonal diagonalization we have $\bc{\D} = \bc{\D}^T$ because $\bc{\D}$ is diagonal. Thus, if $\bc{\A}$ is orthogonally diagonalizable, we know that
$$
\bc{\A} = \rc{\P}\bc{\D}\rc{\P}^T = \rc{\P}^{T^T}\bc{\D}^T\rc{\P}^T = (\rc{\P}\bc{\D}\rc{\P}^T)^T = \bc{\A}^T
$$
which implies that $\bc{\A}$ is symmetric.
(2) If a real-valued matrix $\bc{\A}$ is symmetric, it must be orth. diagonalizable.
For this direction, we need the Schur decomposition. By assumption $\bc{\A}$ is symmetric and real-valued, so that $\bc{\A}^* = \bc{\A}^T = \bc{\A}$. Let $\bc{\A} = \rc{\U}\bc{\T}\rc{\U}^*$ be its Schur decomposition.
From the symmetry of $\bc{\A}$, we have $\rc{\U}\bc{\T}\rc{\U}^* = (\rc{\U}\bc{\T}\rc{\U}^*)^* = \rc{\U}\bc{\T}^*\rc{\U}^*$, so $\bc{\T} = \bc{\T}^*$. This tells us two things. First that all values off the diagonal are zero (remember that $\bc{\T}$ is upper triangular), so $\bc{\T}$ is actually diagonal. Second, that the values on the diagonal are equal to their own conjugate so they must be real values.
This gives us a real-valued diagonalization $\bc{\A} = \rc{\U}\bc{\T}\rc{\U}^*$. But what about the matrix $\rc{\U}$? Could that still contain complex values? It could, but knowing that $\bc{\A}$ is real-valued, and so are the diagonal values of $\bc{\T}$, we can perform the Schur decomposition specifically so that $\rc{\U}$ ends up real valued as well.
Follow the construction of the Schur decomposition. In the base case, $\rc{\U}$ is real-valued by definition. In the inductive step, assume that we can choose $\rc{\V}$ real-valued for the case $n-1$. When we choose the eigenvector for $\bc{\lambda}$, we choose a real eigenvector. These always exist for real eigenvalues (proof in the appendix). When we choose the other columns of $\rc{\W}$ we choose real valued vectors as well.
This means that $\rc{\W}$ and $\rc{\V}'$ are real, so their product $\rc{\U}$ is real as well.
That completes the proof: if we perform the Schur decomposition in such a way that we choose real vectors for $\rc{\W}$ where possible, the decomposition of a symmetric matrix gives us a diagonal real-valued matrix $\bc{\T}$ and an orthogonal matrix $\rc{\U}$.
Conclusion
It’s been a long road, but we have finally reached the end. It’s worth looking back at all the preliminaries we discussed, and briefly seeing why exactly they were necessary to show this result. Let’s retrace our steps in reverse order.
The last thing we discussed, before the proof of the spectral theorem was the Schur decomposition. Its usefulness was clear: the Schur decomposition is the eigendecomposition, if we’re careful about its construction. The main benefit of the Schur decomposition is that it always works. With the real-valued eigendecomposition, we knew that it sometimes exists and sometimes doesn’t. From that perspective it’s very difficult to characterize the set of matrices for which it exists. The Schur decomposition allowed us to zoom out to the set of all matrices, which made the question easier to analyze.
The complex numbers make this possible. Filling matrices and vectors with complex numbers gives us a Schur decomposition for all matrices. The key to this is that the construction of the Schur decomposition requires us to pick an eigenvalue and corresponding eigenvector for various matrices. This is only possible if we allow for complex eigenvalues.
This result, that every $n \times n$ matrix as $n$ eigenvalues if complrx values are allowed, follows from two ideas. The first is the the characteristic polynomial. This is an $n$-th order polynomial, constructed from an $n \times n$ matrix $\bc{\A}$, that is zero, exactly when the determinant of $\bc{\A} - \bc{\lambda}\I$ is zero. This means that the roots of the characteristic polynomial are the eigenvalues. The second idea is the fundamental theorem of algebra which tells us that every $n$-th order polynomial has exactly $n$ roots in the complex plane, counting multiplicities.
That gives us the spectral theorem, and as we saw in the last part, the spectral theorem gives us principal component analysis.
Now that we know how PCA works, why it works, and we have a thorough understanding of the spectral theorem, there is only one question left: how do we implement it? There are a couple of ways to go about this, but the best option by far is to make use of the singular value decomposition (SVD). This is a very versatile operation, which has many uses beyond the implementation of PCA. We will dig into the SVD into the next and final part of this series.
Appendix
Proofs and Lemmas
Given a polynomial $p(z)$ of degree $n$ and a linear factor $z - r$, there is a polynomial $q(z)$ of degree $n-1$ and a constant $c$, called the remainder such that $$p(z) = (z-r)\bc{q(z)} + \rc{d} \p$$
Proof.
Base case. Let $n=1$. Assume we are given $p(z) = \bc{c_1}z + \bc{c_0}$, and some $r$. Define the 0-order polynomial $\bc{q(z)} = \bc{c_1}z$ and the remainder $\rc{d} = \rc{r c_1 + c_0}$. This gives us
$$(z-r)\bc{q(z)} + \rc{d} = (z-r)\bc{c_1} + \rc{r c_1} + \rc{c_0} = p(z)\p$$Induction step. If the theorem holds for $n-1$, then we can show that it holds for $n$ also. Assume we are given an $n$-th order polynomial $p(z)$ and some $r$. Let $p_\text{tail}(z)$ consist of all its terms except the highest order one. We can then write:
$$\begin{align*} p(z) &= c_n z^n + p_\text{tail}(z) \\ p(z) &= c_n z^{n-1}z + p_\text{tail}(z) \\ p(z) &= c_n z^{n-1}z \kc{\;- c_n z^{n-1}z} + p_\text{tail}(z) \kc{\;+ c_n z^{n-1}z} \\ p(z) &= (z-r)c_n z^{n-1}z + \oc{p_\text{tail}(z) + c_n z^{n-1}z}\p \\ \end{align*}$$The last two terms are a polynomial of degree $n-1$. By assumption, we can factor this according to the theorem, which gives us some $\bc{q'(z)}$ and $\rc{d'}$ so that
$$\begin{align*} p(z) &= (z-r)c_n z^{n-1} + (z-r) \bc{q'(z)} + \rc{d'} \\ &= (z-r) (c_nz^{n-1} + \bc{q'(z)}) +\rc{d'} \\ \end{align*}$$Where $\bc{q(z)}$ has degree $n-2$, so that if we set $\bc{q(z)} = c_n z^{n-1} + \bc{q'(z)}$ and $\rc{d} = \rc{d'}$, we satisfy the theorem.
Proof. We'll take it as read that this can be done for real valued vectors.
Let $\z^m$ be a real vector containing the magnitudes of the elements of $\z$, and let $\z^a$ be a real vector containing the angles. Construct a set of real vectors orthogonal to $\z^m$ and to each other. Then, for the $i$th element of each of these vectors, including $\z^m$, change the angle from $0$ to $z^a_i$.
Now, note that orthogonality of two of these vectors $\v$ and $\u$ requires that:
$$\begin{align*} 0 &= \sum_i u_i \overline{v_i} = \sum_i u^m_i\angle u^a_i \; \overline{v^m_i\angle v^a_i} = \sum_i u^m_i\angle u^a_i \; v^m_i\angle - v^a_i \\ &= \sum_i u_i\angle z^a_i \; v^m_i\angle - z^a_i = \sum_i u^m_iv^m_i\angle 0 \end{align*}$$In short, the angles cancel out, so the dot product reduces to the real-valued dot product of $\u^m$ and $\v^m$, which is $0$ by construction.
Real eigenvectors
As we’ve seen, for a particular eigenvalue $\bc{\lambda}$ many different eigenvectors $\bc{\A}$ will satisfy $\bc{\A}\x = \bc{\lambda} \x$. These may well be complex, even if $\bc{\A}$ and $\bc{\lambda}$ are both real. In such cases, however, there is always a real-valued eigenvector as well.
To show this, let $\x$ be a complex eigenvector. We can easily show that its conjugate is an eigenvector too. If $\bc{\A}\x = \bc{\lambda} \x$, then conjugating both sides, we get $\overline{\bc{\A}}\overline{\x} = \overline{\bc{\lambda}} \overline{\x}$, and because $\bc{\A}$ and $\bc{\lambda}$ are real, $\bc{\A}\overline{\x} = \bc{\lambda}\overline{\x}$.
This tells us that the sum of $\x$ and its conjugate is an eigenvector as well, since
\[\bc{\A}(\x + \overline{\x}) = \bc{\A}\x + \bc{\A}\overline{\x} = \bc{\lambda}\x + \bc{\lambda}{\overline{\x}} = \bc{\lambda}(\x + \overline{\x}) \p\]The sum of a vector and its conjugate is real, so we have constructed a real-valued eigenvector for $\bc{\lambda}$.