The Singular Value Decomposition
- 7 Aug 2022
- part 1
- 2
- 3
- 5
- get the book!
In the previous parts of this series, we learned that principal components are eigenvectors. Specifically, they are the eigenvectors of the covariance matrix $\bc{\S}$ of our data $\X$.
In this part, we’ll develop a slightly different perspective: that the principal components are singular vectors. Not of the covariance matrix $\bc{\S}$, but of the data matrix $\X$ itself. Singular vectors, which we will define below, are closely related to eigenvectors, but unlike eigenvectors they are defined for all matrices, even non-square ones.
The two perspectives are complementary: they are simply different ways of looking at the same thing. The benefit we get from the singular vectors is that we can develop the singular value decomposition (SVD).

The SVD is firstly, the most popular and robust way of computing a principal component analysis. But it is also something of a Swiss army knife of linear algebra. It allows us to compute linear projections, linear regressions, and many other things.
Put simply, if you want to use linear algebra effectively in data science or machine learning, the SVD is the beginning and the end.
So, a topic well worth a blog post. We’ll focus on the PCA use case first, since that’s what brought us here, but like the eigendecomposition, the rabbit hole goes much deeper, and we’ll finish by looking at some of the other uses of the SVD. We will look in particular detail at the concepts of matrix rank, the pseudo-inverse and the Eckart-Young-Mirsky theorem.
Eigenvalues and singular values
In the previous two parts we explained eigenvalues and eigenvectors in detail. As we saw, these are well-defined and predictable for square, symmetric matrices. What happens if our matrix is not so well-behaved? What if it’s not symmetric, not invertible, or not even square? Do some of the ideas that underlie eigenvalues and eigenvectors still carry over?
The best place to start is the intuition we built at the end of part two, when we discussed normalization. Let’s review what we said there.
Let’s say that we have a dataset consisting of a set of feature vectors $\x$. We assume that there is some unobserved data $\z$, which is standard-normally distributed, and that a linear transformation $\x = \bc{ \A}\z + \oc{\t}$ has transformed it into to the data we observed.

What we saw in part 2, is that if we can find $\bc{\A}$ from the observed data, then the way in which $\bc{\A}$ stretches space gives us the principal components of the data.
More specifically, imagine taking the (hyper)sphere of all the unit vectors, and transforming them all by $\bc{\A}$. The result is an ellipsoid, and the major axis of this ellipsoid—the direction in which it bulges out the most—is the principal component of the data.

We’ll start with that intuition: the direction in which space is stretched the most by a transformation is important, and see what it gets us when we apply it to general matrices.
Note that this is not an eigenvector of $\bc{\A}$ (It’s an eigenvector of the covariance $\bc{\S}$, but we’ll get to that later). An eigenvector of $\bc{\A}$ is avector whose direction doesn’t change when multiplied by $\bc{\A}$. This is different, in general, from the direction in which the transformation has the greatest effect.

We can now define the rest of the axes of our resulting ellipsoid in the same way we did with the principal components: for the second axis, we constrain it to be orthogonal to the first, and then see in which direction $\bc{\A}$ cause the greatest stretch. For the third, we constrain it to be orthogonal to the first and second, and so on.
In this fashion, we get a series of vectors of “greatest stretch” that are all orthogonal to each other.
The reason we are revisiting these intuitions is that they still hold if $\bc{\A}$ isn’t square. If we allow any matrix, including non-square ones, we can still carry this particular intuition over from the principal components. Let $\gc{\M}$ be any matrix, with dimensions $n \times m$. The multiplication
\[\y = \gc{\M} \x\]maps a vector $\x \in \mR^m$ to a vector $\y \in \mR^n$. If we constrain $\x$ to be a unit vector, then the possible inputs form a (hyper)sphere in $\mR^m$. This sphere is mapped to an ellipsoid in $\mR^n$. We don’t need to know all the details about what ellipsoids are, just the basics: they are linear transformations of spheres, and the axes of the ellipsoid are the directions where it bulges the most (with the second axis the biggest bulge orthogonal to the first, and so on).
For some matrices, for instance singular square ones, the resulting ellipsoid is not fully $n$-dimensional, but of some lower dimensionality. For instance, if $m = n = 3$, there are matrices that produce a 2D ellipse, or even a 1D ellipsoid (a line segment). The matrix could even compress everything into a single point, which we’ll call a 0D ellipsoid.

The same is true for matrices where $n$ is bigger than $m$, for instance a $3 \times 2$ matrix. No linear transformation will turn a 2D sphere into a 3D ellipsoid, so the ellipsoid we get from a $3 \times 2$ matrix must be at most 2 dimensional.
Nevertheless, the output is always an ellipsoid of some dimension, so our intuition carries over. We can always ask in which direction the resulting ellipsoid bulges out the most. It’s just that after a few directions, the remainder may all be compressed to $0$. For now, let’s see what we can say about the directions that aren’t.
So, the question is which unit vector is stretched the most by our matrix $\gc{\M}$? we can state this as an optimization problem:
$$\begin{align*} \argmax{\x} &\;\; \|\gc{\M}\x\| \\ \text{such that} &\;\; \|\x\| = 1 \p \end{align*}$$
This problem simply asks for the input $\x$ for which the resulting vector $\gc{\M}\x$ has maximal magnitude, subject to the constraint that $\x$ is a unit vector.
To find a solution to this problem, we can rewrite both norms as dot products. In the constraint, we know that setting the norm equal to 1 is the same as setting the dot product $\x^T\x$ equal to one. In the optimization objective, the norm and the dot product aren’t the same value (one is the square root of the other), but they are maximized at the same $\x$. So, we get:
$$\begin{align*} \argmax{\x} &\;\; \x^T\gc{\M}^T\gc{\M}\x \\ \text{such that} &\;\; \x^T\x = 1 \p \end{align*}$$
Something quite exciting has happened here. By one simple rewriting step, the maximum of the linear function $\gc{\M}\x$ has become the maximum of the quadratic function $\x^T\bc{\S}\x$, with $\bc{\S} = \gc{\M}^T\gc{\M}$.
This is similar to what we derived in part two: there, we started with a (square) transformation matrix $\bc{\A}$, which took our imagined standard-normally distributed data into the form we observed. We showed that $\bc{\A}$ could be derived from the covariance matrix $\kc{\frac{1}{n}}\X^T\X$ by the relation $\bc{\A}\bc{\A}^T = \kc{\frac{1}{n}}\X^T\X$, and that optimizing for the direction of maximum stretch under $\bc{\A}$ corresponds to the direction in which the quadratic form $\x^T\left(\bc{\A\A}^T\right)\x$ is maximized.
Most importantly, we saw that maximizing the value $\x^T\bc{\S}\x$ gives us the principal eigenvector of $\bc{\S}$. What we are seeing here is that the same thing holds for any matrix $\gc{\M}$. Optimizing for maximum stretch gives us a direction that is equal to the first eigenvector $\rc{\v}$ of $\gc{\M}^T\gc{\M}$. Using this we can work out the relation between the amount that $\rc{\v}$ is stretched in the multiplication $\gc{\M}\rc{\v}$, and the corresponding eigenvalue of $\gc{\M}^T\gc{\M}$:
\[\|\gc{\M}\rc{\v}\|^2 = \rc{\v}^T\gc{\M}^T\gc{\M}\rc{\v} = \rc{\v}^T\bc{\lambda}\rc{\v} = \bc{\lambda}\rc{\v}^T\rc{\v} = \bc{\lambda} \p\]That is, if $\rc{\v}$ is an eigenvector of $\gc{\M}^T\gc{\M}$ with eigenvalue $\bc{\lambda}$, then multiplying $\rc{\v}$ by $\gc{\M}$ stretches $\rc{\v}$ by $\sqrt{\bc{\lambda}}$.
Moreover, even though $\gc{\M}$ may be non-square or singular, we know that $\gc{\M}^T\gc{\M}$ is always symmetric, which tells us that it has exactly $m$ real eigenvalues, including multiplicities. The square roots of these eigenvalues indicate how much $\gc{\M}$ stretches space along the various axes of the ellipsoid we get if we transform the unit vectors by it.
We call these values the singular values of $\gc{\M}$. For each singular value $\gc{\sigma}$, we have used two vectors in its definition. The unit vector $\rc{\v} \in \mR^m$ which we multiplied by $\gc{\M}$ and the vector that resulted from the multiplication. The latter has length $\gc{\sigma}$ so we can represent it as $\gc{\sigma}\rc{\u}$, where $\rc{\u} \in \mR^n$ is also unit vector. With this, we can make our definition of the singular vectors similar to that of the eigenvectors: if $\gc{\sigma}$ is a singular value of $\gc{\M}$, then for its two singular vectors $\rc{\v}$ and $\rc{\u}$
$$\begin{align*} \gc{\M}\rc{\v} &= \rc{\u}\gc{\sigma} \\ \end{align*}$$
We call $\rc{\v}$ the right singular vector of $\gc{\sigma}$ and $\rc{\u}$ the left singular vector.
You may ask what happens if an eigenvalue of $\gc{\M}^T\gc{\M}$ is negative. We know that all eigenvalues are real, but we don’t know that they are all positive. And we’ve defined the corresponding singular values as their square roots.
So, does the corresponding singular value of $\gc{\M}$, become undefined, or complex? The answer is that we can prove that this doesn’t happen. Note that if we pass a unit eigenvector $\rc{\v}$ of $\bc{\A}$ into its quadratic $\rc{\v}^T\bc{\A}\rc{\v}$, the result is its eigenvalue $\rc{\v}^T\bc{\lambda}\rc{\v} = \bc{\lambda} \kc{\v^T\v}$. Now, let $\y = \gc{\M}\x$. Then if $\x$ is an eigenvector of $\gc{\M}^T\gc{\M}$, the quadratic $\x^T\gc{\M}^T\gc{\M}\x = \y^T\y$ is the corresponding eigenvalue. This is simply the sum of the squared elements of $\y$. Whether these are positive or negative, the result is always nonnegative, which shows an eigenvalue of $\gc{\M}^T\gc{\M}$ will always be non-negative.
So, we can be sure that there are always $m$ nonnegative singular values for $\gc{\M}$, even though some of them may be zero.
Singular vectors and principal components
Before we develop the singular values and vectors further, let’s see what their relevance is in the context of principal component analysis. In PCA, we start with a data matrix $\X$, of size $n \times m$, which arranges the $n$ instances in our data along the rows, and the $m$ features of each along the columnns.
We can ask what the singular values of $\X$ are. You may be able to predict the answer, but first let’s look at what how this squares with our intuition of singular values. We said that they represent the maximal amount multiplying a vector by $\X$ stretches that vector. What does it mean to multiply a vector by the data matrix?
Let’s take a vector $\bc{\bp} \in \mR^m$, and let’s assume $\bc{\bp}$ is a unit vector. That way, we are limited in how big we can make each entry. Now multiply $\y = \X\bc{\bp}$. We get a vector of length $n$: one value for each instance $\x$ in our data, which is the dot product of that instance and our vector $\bc{\bp}$. This value is high if the features of the instance match the corresponding values of $\bc{\bp}$ in magnitude and sign: they should be big where $\bc{\bp}$ is big and negative where $\bc{\bp}$ is negative.
That is, the dot product expresses a kind of similarity between $\bc{\bp}$ and the instances in our data. The elements of $\y$ tell us which instances in the data "match" $\bc{\bp}$ the best. This means that the vector $\bc{\bp}$ that is stretched the most by $\X$, is the vector that is most similar to all instances. This is a tradeoff: making it more similar to one instance may make it less similar to other instances. Balancing this over all instances, we get the direction that maximizes $\|\y\|$: the first singular vector of $\X$.
If we assume that the data is mean centered, we can imagine this direction pivoting around the origin, averaging the angles to all instances, proportional to how far from the origin each instance is. This should remind you of how we plotted the first principal component earlier.

It’s not hard to prove that this direction of maximal stretch is indeed the first principal component. As we’ve seen the maximal direction is an eigenvector of the matrix $\X^T\X$. What we also saw, in part two, is that the covariance matrix is estimated with $\kc{\frac{1}{n}}\X^T\X$.
The constant factor $\kc{\frac{1}{n}}$ doesn’t really matter much for our purposes. If we diagonalize $\X^T\X$ as $\rc{\P}^T\bc{\D}\rc{\P}$, then we can write $\rc{\P}^T\kc{\frac{1}{n}}\bc{\D}\rc{\P}$ for the properly normalized covariance. In other words $\X^T\X$ and $\kc{\frac{1}{n}}\X^T\X$ have the same eigenvectors, and their eigenvalues only differ by a multiplicative constant $\kc{\frac{1}{n}}$.
Thus, the directions corresponding to the singular values of $\X$ are the same as the eigenvectors of the covariance matrix. We’ve already established that the singular values of $\X$ are the square roots of the corresponding eigenvalues of $\X^T\X$, so we can say that they are proportional to the eigenvalues of $\bc{\S}$.
We can now show that the singular values and eigenvalues are in some sense generalizations of standard deviation and variance. To illustrate, assume that our data $\X$ is one-dimensional. In this case, we could estimate the variance with the formula:
$$ \text{var } \X = \kc{\frac{1}{n}} \sum_i {X_{i1}}^2 $$
which we can also write as
$$ \kc{\frac{1}{n}} \X^T\X = \X'^T\X' $$
with $\X’ = \kc{\frac{1}{\sqrt{n}}} \X$.
In this case ${\X’}^T\X’$ has one eigenvalue, which is simply the scalar value ${\X’}^T\X’$. As shown above, this corresponds to the estimated variance of the data. The corresponding singular value of $\X’$ is its square root: the standard deviation.
In short, if we ignore a scaling factor of $\frac{1}{\sqrt{n}}$, the singular values of $\X$ are analogous to the standard deviation and the eigenvalues of the covariance matrix $\X^T\X$ are analogous to the variance.
The singular value decomposition
When we developed eigenvalues and eigenvectors, we saw that they allowed us to decompose square matrices as the product of three simpler matrices: $\bc{\A} = \rc{\P}\bc{\D}\rc{\P}^T$. We can do the same thing with singular values and vectors.
We’ve seen that any matrix has singular values, which correspond to two kinds of singular vectors, defined in a way that is similar to the way eigenvectors are defined. Here, we have the eigenvalue definition on the left and the singular value definition on the right
$$ \bc{\A}\rc{\w} = \rc{\w}\bc{\lambda} \hspace{10em} \gc{\M}\rc{\v} = \rc{\u}\gc{\sigma} \p $$
From the definition of the eigenvalue and vector, we managed to construct a decomposition of $\bc{\A}$. A straightforward way to do this is the following recipe.
- Assume that the $n \times n$ matrix $\bc{\A}$ has $n$ real eigenvalues $\bc{\lambda}_i$, with unit eigenvectors $\rc{\w}_i$.
- Arrange the eigenvectors as columns of a matrix so that we get $\bc{\A}\left[\rc{\w}_1 \ldots \rc{\w}_n\right] = \left[\rc{\w}_1\bc{\lambda}_1 \ldots \rc{\w}_n\bc{\lambda}_n\right]$
- Let $\rc{\P} = \left[\rc{\w}_1 \ldots \rc{\w}_n\right]$ and $\bc{\D} = \text{diag}(\bc{\lambda}_1 \ldots \bc{\lambda}_n)$ so that $\bc{\A}\rc{\P} = \rc{\P}\bc{\D}$
- Note that $\rc{\P}$ is orthonormal, so that $\bc{\A} = \rc{\P}\bc{\D}\rc{\P}^T$
The fact that the eigenvectors are orthogonal comes from the iterative way in which we chose them: each was chosen to be orthogonal to all the previous choices. We did the same for the singular vectors. The assumption that we have $n$ real eigenvalues comes from the spectral theorem.
One thing we haven’t examined yet in any detail, is what happens if our eigenvectors are zero. This can happen if we have a square, symmetric matrix which is non-invertible, like
\[\begin{pmatrix}~1 & \kc{0}\\ \kc{0}& \kc{0} \end{pmatrix} \p\]In such cases, we get one or more $\bc{0}$ eigenvalues. What are the corresponding eigenvectors? In many ways it doesn’t matter: the defining relation $\bc{\A}\rc{\w} = \rc{\w}\bc{0}$ always holds, whatever $\rc{\w}$ we choose. To make the above recipe work, all we need to do is to choose $\rc{\w}$ so that it is a unit vector, and orthogonal to any $\rc{\w}$ we already chose.
If we try to follow the same recipe with the singular vectors, we might get something like this.
- Assume that the $n \times m$ matrix $\gc{\M}$ has $k$ singular values $\gc{\sigma}_i$, with unit left and right singular vectors $\rc{\u}_i \in \mR^n$ and $\rc{\v}_i\in \mR^m$.
- Arrange the singular vectors as columns of matrices so that we get $\gc{\M}\left[\rc{\v}_1 \ldots \rc{\v}_k\right] = \left[\rc{\u}_1\gc{\sigma}_1 \ldots \rc{\u}_k\gc{\sigma}_k\right]$
- Let $\rc{\V} = \left[\rc{\v}_1 \ldots \rc{\v}_k\right]$, $\rc{\U} = \left[\rc{\u}_1 \ldots \rc{\u}_k\right]$ and $\gc{\Sig} = \text{diag}(\gc{\sigma}_1 \ldots \gc{\sigma}_k)$ so that $\gc{\M}\rc{\V} = \rc{\U}\gc{\Sig}$
This is as far as we get. There aren’t necessarily sufficient singular values to ensure that $\rc{\V}$ is square. That means $\rc{\V}$ is not invertable, so we can’t take it to the other side of the equation.
A simple solution is to extend $\rc{\V}$ to a complete basis. We know that the $k$ singular vectors making up $\rc{\V}$ are mutually orthogonal, and we know that we can always choose $m - k$ additional unit vectors orthogonal to these and to each other. If we add them to $\rc{\V}$ as columns, $\rc{\V}$ becomes an $m \times m$ orthonormal matrix.
If we add one such vector $\rc{\v}'$ to $\rc{\V}$, what do we need to change to keep our equation $\gc{\M}\left[\rc{\v}_1 \ldots \rc{\v}_k\right] = \left[\rc{\u}_1\gc{\sigma}_1 \ldots \rc{\u}_k\gc{\sigma}_k\right]$ intact? We need to extend the right with the vector $\gc{\M}\rc{\v}'$. What can we say about this vector? First, we can always write any vector as a unit vector times a scalar length, so let's call it $\rc{\u}'\gc{\sigma}'$.
$$ \gc{\M}\left[\rc{\v}_1 \ldots \rc{\v}_k\; \rc{\v}'\right] = \left[\rc{\u}_1\gc{\sigma}_1 \ldots \rc{\u}_k\gc{\sigma}_k\; \rc{\u}'\gc{\sigma}'\right] $$
Note that we assumed that we have all $k$ singular values of $\gc{\M}$ already. This means that there is no vector $\rc{\v}$ orthogonal to all $\rc{\v}_i$ such that $\|\gc{\M}\rc{\v}\| > 0$, or it would be a candidate for the $k+1$th singular vector. Therefore, $\|\gc{\M}\rc{\v}'\| = 0$.
This means that we can set $\gc{\sigma}' = 0$ and choose $\rc{\u}'$ however we like. We will choose some vector that is orthogonal to all $\rc{\u}_i$ already chosen.
We could just keep adding vectors like this until $\rc{\V}$ is square, and it would be orthonormal, so we would be allowed to move it to the other side. But we’d be missing a trick if we stopped there. The matrix $\gc{\M}$ represents a function from one space, $\mR^m$ to another $\mR^n$. If we make $\rc{\V}$ square and orthonormal, we have constructed an orthonormal basis for $\mR^m$, just like the analogous $\rc{\P}$ is a basis in the eigendecomposition. It would be quite nice, if we could ensure that $\rc{\U}$ is also an orthonormal basis for $\mR^n$. That way, we would have two orthonormal bases $\rc{\U}$ and $\rc{\V}$ for the two spaces that $\gc{\M}$ transforms between, and a diagonal matrix of singular $\gc{\Sig}$ values in the middle.
To do this we need to add different numbers of orthogonal vectors to $\rc{\V}$ and $\rc{\U}$. $\rc{\V}$ needs $k-m$ extra vectors to become $m \times m$, and $\rc{\U}$ needs $k-n$ extra vectors to become $n \times n$. The trick to accomplish this is to make $\gc{\mathbf \Sigma}$ non-square. We make $\gc{\mathbf \Sigma}$ an $m \times n$ matrix, with all zeros except for the diagonal of the top $k\times k$ matrix in the top left, which contains the singular values. Here is an illustration.

We see that the effect of extending $\rc{\V}$ with orthogonal vectors is to add zero columns to the product $\gc{\M}\rc{\V}$. This is not surprising, since we noted already that these must be in the null space of $\gc{\M}$.
On the right, the product $\rc{\U}\gc{\Sig}$ needs to be equal to $\gc{\M}\rc{\V}$. The extra zero columns can easily be added by adding zero columns to $\gc{\Sig}$.
How about the extra basis vectors we would like to add to $\rc{\U}$? We need to add rows to $\gc{\Sig}$ in order to make the matrix dimensions match. If the rows we add are zero rows, then we can be sure that when we multiply the two matrices, any entry in any column added to $\rc{\U}$ will be multiplied by $0$, so it won’t affect the product $\rc{\U}\gc{\Sig}$.
Here is the process in three steps:



Now, we can safely take $\rc{\V}$ to the other side (that is, multiply both sides by $\rc{\V}^{-1}$). Since we’ve carefully constructed $\rc{\V}$ to be orthonormal, we know that $\rc{\V}^{-1} = \rc{\V}^T$ and we get:
\[\gc{\M} = \rc{\U}\gc{\Sig}\rc{\V}^T\]Where, to reiterate:
- $\gc{\M}$ is any $n \times m$ matrix. We call the number of singular values it has $k$.
- $\rc{\V}$ and $\rc{\U}$ are orthogonal matrices of $m\times m$ and $n \times n$ respectively. The first $k$ columns of each are the right and left singular vectors respectively.
- $\gc{\Sig}$ is an $n\times m$ matrix with all entries $0$ except the first $k$ elements of the diagonal, which correspond to the singular values of $\gc{\M}$.
Here it is in a diagram.

This is called a full singular value decomposition. It gives us all singular values, and two complete orthonormal bases for $\mR^n$ and $\mR^m$.
This is not a very economical way of representing $\gc{\M}$: all these matrices are very big. Let’s see if we can trim the fat a little bit.
If we look at $\gc{\Sig}$, we see that we added a lot of zeros, in order to move $\rc{\V}$ over to the right. It seems reasonable, that all these zeros, and their associated basis vectors, aren’t actually necessary to represent $\gc{\M}$.
How much do we need? We know that $\gc{\M}$ maps the axes of a sphere in the input space to the axes of an ellipsoid in the output space. Each singular value corresponds to one such mapping from axis to axis. We also know that to get from the equation with only the singular values and vectors to the full SVD, we only added zeros to $\gc{\Sig}$ and null-space vectors to $\rc{\V}$. It’s hard to escape the intuition that we had what we needed already before we extended $\rc{\V}$ and $\rc{\U}$ to be square, and the singular vectors and values by themselves already provided a complete description of $\gc{\M}$.
To prove this, we can walk back the exact steps we took to get to the full SVD, but now with $\rc{\V}$ on the right hand side. First, here is the full SVD, for reference.

We’ve highlighted how the elements of $\rc{\U}\gc{\Sig}$ in the middle are computed: each is the dot product of a row of $\rc{\U}$ and a column of $\gc{\Sig}$. The elements of each are matched up, multiplied and the result is summed together. What we see here, is that the elements of the columns we added to $\rc{\U}$, the ones that don’t correspond to a singular value, are always matched up to a zero. Removing them won’t change the dot product, and thus won’t change the elements of the matrix $\rc{\U}\gc{\Sig}$. This means we can safely remove the columns we added to $\rc{\U}$, and each corresponding row of $\gc{\Sig}$.
Here’s the result:

We can use the same logic on the multiplication of $\rc{\U}\gc{\Sig}$ by $\rc{\V}^T$. The added rows of $\rc{\V}^T$ are always matched up to zero columns of $\rc{\U}\gc{\Z}$. Removing these will not affect the value of each dot product. To remove the zero columns from $\rc{\U}\gc{\Sig}$, all we need to do is remove the rightmost block of zeros.
Removing all three, we arrive at a more economical representation of $\gc{\M}$:

It turns out that without extending $\rc{\V}$ and $\rc{\U}$ to full bases, we already had a complete decomposition of $\gc{\M}$, although we had to first make the extension to prove the fact.
We've done a lot of variable reassignments here: first using $\rc{\V}$ to refer to just the singular vectors, then extending it to a square matrix, and then clipping it back again. To make our notation more precise, from now on we'll use $\rc{\U}$ and $\rc{\V}$ for the complete, square, basis matrices and $\rc{\U}_r$ and $\rc{\V}_r$ for the matrices made up of the first $r$ columns of each.
If we assume that $\gc{\M}$ has $k$ singular values, we can now write this latest decomposition as:
$$\gc{\M} = \rc{\U}_k\gc{\Sig}_k{\rc{\V}_k}^T $$
This is called the compact SVD.
Finally, if we’re not interested a perfect decomposition, we can extract only the top $r < k$ singular values and vectors. If we then construct the matrices $\rc{\V}_r$ with the corresponding right singular vectors, $\rc{\U}_r$ with the corresponding left singular vectors and $\gc{\Sig}_r$ with these singular values along the diagonal, we can still perform the multiplication
$$ \gc{\M}_r = \rc{\U}_r\gc{\Sig}_r{\rc{\V}_r}^T \p $$
This is called the truncated SVD. It is not a proper decomposition of $\gc{\M}$, since $\gc{\M}_r$ won't be equal to $\gc{\M}$, but it will be, in a very precise sense, the closest we can get. We'll dig into the details of that later.
Principal Component Analysis by SVD
Before we move on, let's convince ourselves we can actually compute the SVD for a given $\gc{\M}$. The derivation of the SVD we've used above suggests a simple algorithm to decompose a matrix $\gc{\M}$. We can use gradient descent to find the singular vector $\rc{\v}$ for which $|| \gc{\M}\rc{\v} ||$ is maximal, subject to the constraint that $\rc{\v}$ is a unit vector. Once gradient descent has converged, we find the next vector in the same way, but with the added constraint that it is orthogonal to all the vectors we've already chosen.
If we stop collecting vectors at some arbitrary $r$, we get the truncated SVD. If we stop when we see the first $\rc{\v}$ for which $\gc{\M}\rc{\v} = \mathbf 0$, we get the compact SVD, and finally, if we then also extend $\rc{\V}$ and $\rc{\U}$ to full bases, we get the full SVD.
This isn’t the most precise or efficient SVD algorithm, and it isn’t much better than the algorithm that we already developed for computing PCA in part one, but for now it should suffice to convince us that we can compute the SVD. We’ll first see how exactly to implement PCA on the basis of a given algorithm for the SVD. We’ll see some better algorithms in the next part.
Let $\X$ be the data matrix for our mean-centered data, and let $\rc{\U}\gc{\Sig}\rc{\V}$ be its (full) SVD.
It should be clear from the exposition above that once we have the SVD, there isn’t a whole lot left to do.
We know that the principal components are the eigenvectors of $\kc{\frac{1}{n}}\X^T\X$. The constant factor $\kc{\frac{1}{n}}$ affects the eigenvalues, but not the eigenvectors, so we are equivalently looking for the eigenvectors of $\X^T\X$. These are the right singular vectors of $\X$, which are the columns of $\rc{\V}$ in our SVD.
So, the principal components follow directly from the SVD. Let’s look at some of the things we may want to do with the principal components in practice, and see how we would achieve that.
Projecting the data to a lower dimension This is probably the main use case of principal component analysis. Reduce the dimensionality of the data so that we can feed it to some expensive algorithms or visualize it in 2D or 3D. To reduce the data to $r$ dimensions, we need to project it orthogonally onto the first $r$ principal components. We achieve this by computing the SVD truncated to $r$, and computing $\Z = \X\rc{\V}_r$.
As we can see in the decomposition, this is equal to $\rc{\U}_r\gc{\Sig}_r$. This multiplication is cheaper and more stable to compute, because $\gc{\Sig}_r$ is a diagonal matrix.
Recovering the data As we saw in part one, we can partly reconstruct the data based on these lower-dimensional representations. Each element $z_i$ of the latent representation tells us that we should multiply the $i$-th principal component by this value, and and sum all these together. In matrix terms $\X’ = \Z{\rc{\V}_r}^T = \rc{\U}_r\gc{\Sig}_r{\rc{\V}_r}^T$.
Whitening In whitening, discussed in part 2, we don’t want to reduce the dimensionality of the data, we want to transform it so that it takes the shape of a standard normal distribution (or as close as we can get with a linear transformation). For this, we need a full basis $\rc{\V}$, so we should compute at least the first $m$ singular vectors, and extend $\rc {\V}$ to be square if necessary. Then, we can compute a complete represention of the data $\Z = \X\rc{\V}^T = \rc{\U}_m\gc{\Sig}_m$.
This projects the data onto the eigenbasis, but we still need to scale the data along each axis, so that it has unit variance. In 1D, we to this by dividing by the standard deviation, and we characterized the singular values as the analogue of the standard deviation, so it would be intuitive if we should divide by the singular values.
To prove this, remember from part two that the whitening transformation is the inverse of $\x = \bc{\A}\z + \oc{\t}$. That is
\[\z = \bc{\A}^{-1}(\x - \oc{\t}) = \bc{\A}^{-1}\x - \kc{{\A}^{-1}{\t} }\p\]We’ll assume that our data is mean-centered, so $\oc{\t} = {\mathbf 0}$.
We also saw that $\bc{\A}$ should be a square root of the covariance matrix:
\[\bc{\A}\bc{\A}^T = \kc{\frac{1}{n}}\X^T\X\]If we expand $\X$ into its SVD, we see that the SVD allows us to compute this square root:
\[\begin{align*} \bc{\A}\bc{\A}^T &= \kc{\frac{1}{n}}\X^T\X \\ &= \kc{\frac{1}{n}} (\rc{\U}\gc{\Sig}\rc{\V}^T)^T\rc{\U}\gc{\Sig}\rc{\V}^T \\ &= \kc{\frac{1}{n}} \rc{\V}\gc{\Sig}\rc{\U}^T\rc{\U}\gc{\Sig}\rc{\V}^T \\ &= \kc{\frac{1}{\sqrt{n}}} \rc{\V}\gc{\Sig} \kc{\frac{1}{\sqrt{n}}}\gc{\Sig}\rc{\V}^T \\ \end{align*}\]This means that with $\bc{\A} = \kc{\frac{1}{\sqrt{n}}}\rc{\V}\gc{\Sig}$ we have found our square root of the covariance. Not only that, we also have it in a form that is easy to invert:
\[\begin{align*} \bc{\A}^{-1} &= \left(\kc{\frac{1}{\sqrt{n}}}\rc{\V}\gc{\Sig}\right)^{-1} \\ &= \kc{\sqrt{n}}\gc{\Sig}^{-1}\rc{\V}^T \\ \end{align*}\]where $\gc{\Sig}^{-1}$ consists simply of $\gc{\Sig}$, but with the diagonal elements inverted. We can now use $\bc{\A}^{-1}$ to normalize our data.
Note that because we computed an SVD, the inversion, which is normally a very unstable operation, becomes very stable. It isolates the inversion of scalars to the diagonal elements of a matrix, and reduces the rest to transposing an orthogonal matrix.
So that’s the SVD: a decomposition that is so similar to PCA, you may be wondering why we separate the two at all? Isn’t computing the SVD the same as computing the PCA? The answer is that the SVD is not just a way to compute a PCA. It can be used to compute many other things as well.
Next, we’ll take a look at some of the most important things the SVD can do for us, beside computing a PCA. Along the way we’ll try to build some additional intuition for how the SVD operates.
The first use case will provide an intuition for the number of singular values we can expect in a matrix.
Rank
Think back to the income dataset from the very first part, before we made it more realistic by adding some noise.

As we noted then, even though this data is presented as two-dimensional—with two features—it is really inherently one-dimensional. This is easy to see in the picture, since the data lies on a line. What does this look like in the data matrix $\X$? Note that each $x$ value can be derived from the $y$ value by multiplying it by $3$. This means that the second column of our data matrix is a multiple of the first. For every row $r$, $\X_{r1} = 3\X_{r2}$.
Interestingly, the same holds true in the vertical direction. If we think of each person in the data as a vector, all these vectors point in the same direction. Only their lengths differ. This means that if we fix some arbitrary instance $i$, desribed by $\x_i$, the $i$-th row of $\X$, every other instance (every row in $\X$) can be described as some scalar $m$ times $\x_i$.
In some sense, this tells us that the matrix $\X$ is compressible. We are given $300 \cdot 2 = 600$ numbers, but we really only need one vector in $\mR^{300}$ and a single scalar, or one vector in $\mR^2$ and $299$ scalars.
How much a matrix can be compressed in this way is indicated by its rank. In this case the horizontal reduction tells us that the matrix has a column rank of one—we can represent it by just one of its columns and a bunch of multipliers.
It has row rank of one as well—we can also represent it by one of its rows and a bunch of multipliers. We will see in a bit that it is no accident that the row and column rank are the same.
What does it mean to have a higher rank than one? Let’s say that a matrix can be compressed to $n$ columns if a subset of $n$ of its columns is enough to express the rest as a linear combination of these $n$. For instance, if a matrix has column rank of $3$, then there are three column vectors $\a$, $\b$, and $\c$, so that every other column can be expressed as $\rc{a}\a + \rc{b}\b + \rc{c}\c$ with some numbers $\rc{a}, \rc{b}, \rc{c}$ unique to that column. The column rank of a matrix is the smallest number of columns that it can be compressed to, and and the row rank is the smallest number of rows that it can be compressed to.
It’s helpful to draw such a compression in a matrix multiplication diagram. Let’s assume we have a large rectangular matrix $\gc{\M}$ with dimensions $n \times m$ and let’s assume that it has column rank $3$. This means that we can pick three of its columns $\a$, $\b$ and $\c$ and represent all other columns by a set of just three numbers $a$, $b$ and $c$.
Before we draw the diagram, note that $\a$, $\b$ and $\c$ don’t actually have to be columns of $\gc{\M}$. We could, for instance, scale them to unit vectors, and we could still represent all columns of $\gc{\M}$ as linear combinations. The key point is that we can express all column vectors of $\gc{\M}$ in some basis of three vectors. They are all points in a 3D subspace of $\mR^n$.
Now, to our diagram. Put the three basis vectors $\a$, $\b$ and $\c$ side by side in a matrix $\bc{\B}$ of $n \times 3$. For a given column of $\gc{\M}$, we can work out what $\rc{a}$, $\rc{b}$ and $\rc{c}$ should be and put these together in a column vector $\rc{\d}$. Multiplying $\bc{\B}\rc{\d}$ gives us the linear combination $\rc{a}\a + \rc{b}\b + \rc{c}\c$, and thus reconstructs our column vector of $\gc{\M}$. If we work out all the vectors $\rc{\d}$ for all columns of $\gc{\M}$ and concatenate them as the columns of a big $3 \times m$ matrix $\rc{\D}$, then multiplying $\bc{\B}\rc{\D}$ reconstructs all columns of $\gc{\M}$. Or, put simply, $\gc{\M} = \bc{\B}\rc{\D}$.

This is called a rank decomposition of $\gc{\M}$.
Looking at this diagram, we can almost directly deduce one of the more magical facts about ranks: that the column rank is equal to the row rank.
Imagine if we were to follow the same recipe for the row rank. We don’t know the row rank, so let’s call it $k$. If the row rank is $k$, there will be $k$ rows that can serve as a basis for all rows. We concatenate them into a $k \times m$ matrix $\bc{\B}’$ and work out the row vectors $\rc{\d}’$ for each row of $\gc{\M}$. Concatenating these into a matrix $\rc{\D}’$ of $n \times k$, we get $\rc{\D}’\bc{\B}’ = \gc{\M}$. In other words, we get exactly the same diagram, but with the roles reversed.

This means that in the second diagram, we can also interpret $\rc{\D}’$ as representing $k$ column vectors and $\bc{\B}’$ as representing the scalars required to reconstruct the columns of $\gc{\M}$. And from this we can deduce directly what $k$ should be. Since $3$ is the column rank of $\gc{\M}$, it can’t be less than $3$ or we would have found a representation of $\gc{\M}$ in fewer columns (and the rank is the lowest number of columns possible). It also can’t be more than $3$, because then we could go the other way around: start with the second diagram, interpret it as a row rank diagram, and we’d find a representation with fewer rows than $k$, even though $k$ is the row rank. So $k$ must be $3$.
This argument shows us that the column and the row rank of any matrix must be equal. We can drop the qualifier, and just refer to the matrix’s rank. We can also conclude that the maximum possible value of the rank is $\text{min}(n, m)$: the column rank cannot exceed the number of columns, and the row rank cannot exceed the number of rows, so the minimum of these two must be the matrix rank.
A matrix with rank equal to $\text{min}(m, n)$ is called full rank. A matrix that isn’t full rank is called rank deficient.
The rank is a very fundamental property of matrices with many interpretations in many contexts. Here are three examples, the last of which will bring us back to the singular value decomposition.
Dimension of the image of $\gc{\M}$ In part three, to explain the determinant, we modeled the operation of a square matrix as a mapping from a unit cube to a polyhedron. We can extend this intuition to rectangular matrices as well. Take an $n \times m$ matrix $\gc{\M}$. The input space of this matrix is spanned by $m$ unit vectors pointing along the axes of $\mR^m$. If we imagine these as $m$ sides defining a unit cube, then we can ask how this cube is transformed by $\gc{\M}$ into a parallelotope in $\mR^n$.
The input vectors are one-hot, so multiplying one by $\gc{\M}$ just picks out one of the columns of $\gc{\M}$. Thus, we are creating the parallelotope spanned by the columns of $\gc{\M}$. If all of these point in different directions, the parallelotope is of dimension $m$. If we only get $r < m$ unique directions, we get an $r$-dimensional shape.
We also get a shape of less than $m$ diemsions if one or more of the vectors lies in a plane spanned by two of the others, or more generally in an subspace spanned by some of the others. In short, if one of the vectors is a linear combination of the rest.
The rank of $\gc{\M}$ tells us the dimension of the image: the shape we get after operating on a shape of dimension $m$. Since column and row rank are equal, we now know that this is also the dimension of an image of $\gc{\M}^T$. In the image below, we look at the image of the unit cube under a matrix. Since the matrix has rank two, the resulting figure is two-dimensional.

Invertibility and determinants A square matrix $\bc{\A}$ with dimensions $n \times n$ can be invertible. That means that given $\y$, there is always only one $\x$ such that $\y = \bc{\A}\x$. We’ve already seen that the determinant tells us when a matrix is invertible: if the image of the matrix has volume $0$, then the matrix is not invertible. Note that we are talking about $n$-volume here. If the matrix is $3 \times 3$ and the image of the unit cube is 2 dimensional, then it has a nonzero area but not a nonzero volume. In general if the image of an $n \times n$ matrix has nonzero $n$-volume, the determinant of $\bc{\A}$ is zero.
Any shape of dimension less than $n$ has zero $n$-volume: a square has zero volume, and a line has zero area. This means that if the rank tells us that the image of a $\bc{\A}$ has dimension less than $n$, $\bc{\A}$ must have determinant $0$ and must therefore be non-invertible.
The reverse direction also works. If $\bc{\A}$ is full-rank, the image, however small, is $n$-dimensional, and must have a nonzero $n$-volume. If we look at the image of the unit cube, we see that the images of the standard basis vectors must point in different directions if $\bc{\A}$ is full rank, and the resulting parallellotope must have nonzero volume.
This provides one way to check for matrix singularity: if any of the columns is a linear combination of the rest, your matrix must be rank deficient, and therefore non-invertible, and have determinant $0$. If there is no such column, the matrix is full rank, invertible and has nonzero determinant.
Number of singular values Here, we come back to the topic at hand. We’ve defined what singular values are, and how to enumerate them one by one. We’ve seen that this enumeration stops at some point (when $|| \gc{\M}\rc{\v} || = 0$), but we haven’t talked about when we can expect it to stop. How many singular values should we expect a given matrix to have?
You can probably guess the answer, so let’s start there and work backwards: the number of singular values a matrix has, is equal to its rank.
How do we show this? We discussed above that the rank is the dimension of the image of a matrix. That means that if we start with all unit vectors in $\mR^m$, a sphere of dimension $m$, and look at the image of this set under $\gc{\M}$, we will see a $k$-dimensional ellipsoid. This means that the process that enumerates the singular vectors can spit out $k$ mutually orthogonal vectors. After that, every vector $\rc{\v}$ that is orthogonal to the ones already produced must have $\gc{\M}\rc{\v} = \mathbf 0$.
Computing rank
So, that’s rank. A fundamental, and very useful property of matrices. Now, given a matrix $\gc{\M}$, how do we compute its rank? There are many algorithms: QR decomposition, row reductions, etc. The problem with all of these, is that when we encounter a matrix in the wild, there is often a little bit of noise. Either the matrix contains measurements, which are always subject to noise, or it’s the result of some numeric computation, in which case floating point errors probably add a little bit of imprecision.
Any small amount of noise means that, with overwhelming probability, no column vectors will lie in exactly the subspace spanned by the others. The noise will always push it a tiny bit out of the subspace. This will technically make the matrix full rank, but what we are actually interested in, is what rank the matrix would have if we could remove the noise.
This is why the SVD is the preferred way of computing the rank of a matrix. If have a column vector that lies almost but not quite in the subspace spanned by the others, the result is a very small singular value.
To see why, imagine a rank 1 matrix with dimensions $3 \times 3$. This matrix would have all column vectors pointing in the same direction, and the image of the unit sphere would be a line segment. As a result, we get one singular value.
If we apply a tiny bit of noise to one of the columns, one of the vectors in the image won’t quite point in the same direction as the others. As a result, we get an ellipse that looks a lot like a line segment: very thin in one direction. The image has 2 axes, so we get two singular vectors: one very similar to what we had before, for the main axis of the ellipse, and one very tiny one orthogonal to it, representing the extra dimension created by the noise.
If the noise is small, then the singular values created by the noise are of an entirely different magnitude to the original singular values. This is why the SVD helps us to compute the rank in the presence of noise: we simply set a threshold to some low number like $10^{-7}$, and treat any singular value below the threshold as zero. The number of singular values remaining is the rank of our matrix if we ignore the noise.
What if we were to remove the corresponding singular vectors as well? If $r$ is the rank we've established with the method described above, this means performing an $r$-truncated SVD. Multiplying the matrices $\rc{\U}_r$, $\gc{\Sig}_r$, $\rc{\V}_r$ back together gives us a matrix $\gc{\M}'$ which approximates $\gc{\M}$, but removes the singular vectors corresponding to the noise. Can we treat this as a denoised version of our matrix? If so, what can we say about the remainder?
We can answer that question very precisely, but to do so, we’ll first look at how the SVD can help us solve equations.
The pseudo-inverse
A very common use of the singular value decomposition is to solve systems of linear equations. To put that in a familiar context, let’s return again to the example that we started with in part one: the salary dataset. This time, we’ll look at the more realistic version.

When I first showed this picture, I tried to steer you away from seeing this as a linear regression problem, where the task is to predict the variable on the vertical axis from the one on the horizontal. PCA, after all, is an unsupervised method: no feature in our data is marked as the target to be predicted. Instead, we want a compressed representation from which we can “predict” all of them as well as possible.
Let’s forget about PCA for the moment, and let’s return to the supervised setting. If we do want to predict one feature given the others, how does the SVD help us do this, and how does the solution to this problem relate to the solution to the PCA problem?
We’ll stick with linear regression. This means we want to draw a line through these points that provides a prediction for the variable on the vertical axis. We want to choose this line so that the squares of the vertical distance to the data are minimized.
Here’s a comparison to the definition of the first principal component. For the linear regression, we minimize the squares of the vertical distance, while for the principal component, we minimize the squares of the distances across both dimensions.

For a general solution, assume we have $n$ instances with $m$ input features each, collected into an $n \times m$ data matrix $\X$, and that for each instance $\x_i$, we have one target value $y_i$, collected into a vector $\y \in \mR^n$.
Our goal is to find a vector $\bc{\w}$ of $m$ weights, and a scalar $\oc{t}$ so that the prediction ${\x_i}^T\bc{\w} + \oc{t}$ is as close to the target value $y_i$ as possible. Ideally, we'd want to find a $\bc{\w}$ so that ${\x_i}^T\bc{\w}$ is exactly equal to $y_i$ for all instances. Or in matrix notation
\[\X\bc{\w} + \oc{t} = \y\]with $\y$ a long vector collecting all $n$ target values.
In most cases, such an ideal solution is unlikely to exist. Even if there is a perfectly linear relation between the features and the target, there is probably a little noise in the data.
Instead, we'll measure how close our predictions are to the target by the square of the difference between them: $\left({\x_i}^T\bc{\w} + \oc{t} - y_i\right)^2$.
Summing these squares over all instances, our objective becomes
$$ \argmin{\bc{\w}, \oc{t}} \sum_i ( {\x_i}^T\bc{\w} + \oc{t} - y_i )^2 \p $$
We could solve this by gradient descent, or some other standard optimization algorithm, but when it comes to least-squares problems for linear models like these, we can find a more direct solution. Even better, we can get there mostly by geometric intuitions.
First, let’s get rid of the term $\oc{t}$. The simplest trick here is to add a feature to the data whose value is always one. The result is that $\bc{\w}$ gains an extra value which is always added to the output, just like $\oc{t}$ is in the formulation above.
If we assume that this trick has been applied to $\X$ and $\bc{\w}$, our problem reduces to
$$ \argmin{\bc{\w}} \sum_i ( {\x_i}^T\bc{\w} - y_i )^2 $$
or in matrix notation
$$ \argmin{\bc{\w}} \;\;\| \X\bc{\w} - \y \|^2 \p $$
Note that the term $\X\bc{\w}$ is computing a linear combination of the columns of $\X$: each element of $\bc{\w}$ is multiplied by one of the columns of $\X$ and the result is summed together. The space of all linear combinations of the columns of a matrix $\X$ is called its column space, denoted $\text{col}\;\X$. Every possible $\bc{\w}$ results in a unique point $\X\bc{\w}$ in the column space of $\X$. The set of all these points together coincides with the entire column space.
So, we can now say that we are looking for the point in the column space of $\X$ that is closest, by least squares, to the vector $\y$ (which may be outside the column space).

In part one, we saw a simple result called the “best approximation theorem”. It stated that if we have a point $\q$ and a line $\rc{P}$, the closest to $\q$ we can get while staying on the line $\rc{P}$ is the orthogonal projection of $q$ onto $\rc{P}$.
We have a similar situation here. There is a point $\y$ that we want to approximate as best we can, but we have to stay in a specific part of space: not a line, but a subspace. Specifically the column space of $\X$.

Happily, the best approximation theorem holds also when the subspace we’re restricted to is more than a line: the closest we can get to a point $\q$ while staying in some subspace $\rc{S}$ is the orthogonal projection of $\q$ onto $\rc{S}$. In our case, that means that the best approximation to $\y$ within the column space of $\X$ is the orthogonal projection of $\y$ onto $\text{col} \X$.
The first thing we should do is to define what an orthogonal projection means in this context. We’ll call a vector orthogonal to a subspace $\rc{S}$ if it is orthogonal to every vector in $\rc{S}$. Think of a plane intersecting the origin: a vector orthogonal to the plane points out of the plane at a right angle to every direction in the plane.
An orthogonal projection of $\q$ onto $\rc{S}$ is a point $\rc{\hat \q}$ in $\rc{S}$ so that the difference $\q - \rc{\hat \q}$ is orthogonal to $\rc{S}$. Note how this generalizes the one-dimensional case: the line segment pointing out of the line $\rc{P}$ at the orthogonal projection is orthogonal to every vector that points along $\rc{P}$.
Now, we want to show that if we find an orthogonal projection of $\q$ onto $\rc{S}$, that that is the closest we can get to $\q$ while staying in $\rc{S}$. We’ll follow the same logic as we did in the 1D case. Imagine that we have an orthogonal projection $\rc{\hat \q}$ and any other point $\rc{\bar \q}$ in $\rc{S}$. No matter how many dimensions our space has, the three points $\q$, $\rc{\hat \q}$ and $\rc{\bar \q}$ form a triangle.
In this triangle, we know that the points $\rc{\hat \q}$ and $\rc{\bar \q}$ are in $\rc{S}$ so the vector $\rc{\hat \q} - \rc{\bar \q}$ must be as well. Because this vector is in $\rc{S}$, we know that $\q - \rc{\hat \q}$ is orthogonal to it so our triangle has a right angle at $\rc{\hat \q}$.
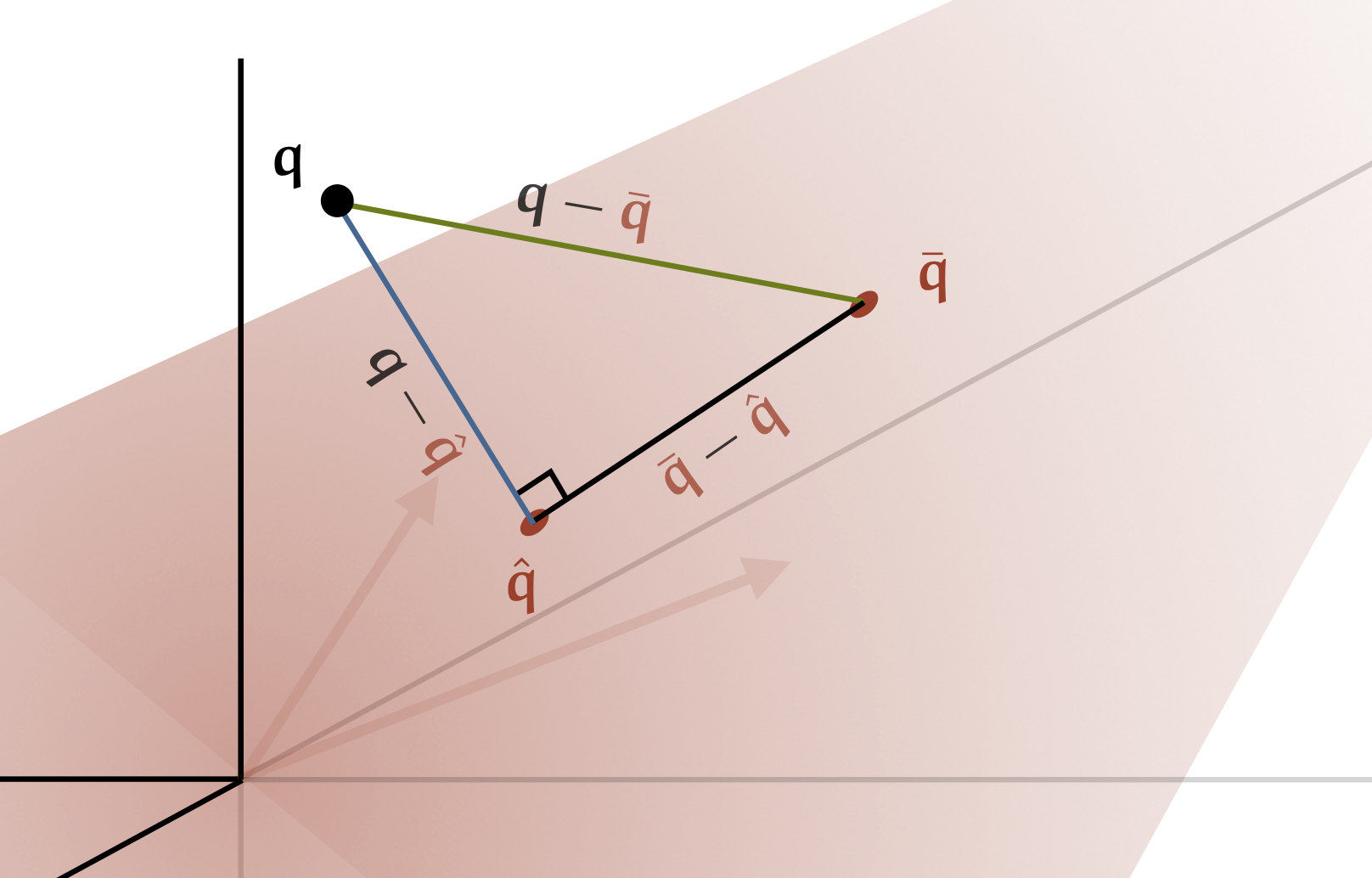
From the image, you can already see that the vector $\bc{\q - \hat \q}$ must be shorter than or equal to $\gc{\q - \bar \q}$. The Pythagorean theorem lets us formalize this:
$$ \|\gc{\q - \bar \q}\|^2 = \|\hat \q - \bar \q\|^2 + \|\bc{\q - \hat \q}\|^2 \p $$
This tells us that the only way $\rc{\bar \q}$ can be as good an approximation as $\rc{\hat \q}$ is if $\|\rc{\hat \q} - \rc{\bar\q}\| = 0$, which implies that they are the same vector.
We haven’t shown that $\rc{\hat \q}$ exists or that it is unique, but if we can find a set of one or more orthogonal projections of $\q$, they must be the closest we can get to $\q$ while staying inside the subspace $S$.
Let’s return to the problem at hand. We’ve noted that the predictions our model $\bc{\w}$ can produce for the data $\X$ are restricted to the column space of $\X$. By the argument above, the closest we can get to the target values $\y$ is the orthogonal projection $\y$ onto this space. The vector $\hat \y = \X\bc{\w}$ provides an orthogonal projection if the vector $\oc{\e}$ pointing from $\hat\y$ to $\y$ is orthogonal to the column space of $\X$.
This happens if it is orthogonal to all columns of $\X$. Any vector orthogonal to all columns is also orthogonal to any linear combination of all columns, so it must be orthogonal to $\text{col}\;\X$.
We can phrase this symbolically as
\[\X^T\oc{\e} = \mathbf 0\]with $\oc{\e} = \y - \hat \y$, and $\mathbf 0$ a vector of zeros. With a bit of filling in and rewriting, we get
\[\begin{align*} \X^T\left(\y - \hat\y\right) &= {\mathbf 0} \\ \X^T\y &= \X^T\hat\y \\ \X^T\y &= \X^T\X\bc{\w} \\ \end{align*}\]This is called the normal equation for our linear problem. Any $\bc{\w}$ that satisfies this equation is a least squares solution. Note that $\X^T\X$ has popped up again.
In fact, we can see here that if $\X^T\X$ is invertible, we can multiply both sides by the inverse and get
\[\left (\X^T\X\right)^{-1}\X^T\y = \bc{\w}\]as a single, unique solution for $\bc{\w}$.
The term $\left (\X^T\X\right)^{-1}\X^T$ is an instance of something called the pseudo-inverse of $\X$, written $\X^\dagger$. We’ll provide a more robust definition later, but it’s interesting to see where the name comes from. Think back to the idealized version of our problem $\X\bc{\w} = \y$. If we had been lucky enough to have a square and full-rank $\X$, we could compute the exact solution by multiplying both sides by the inverse of $\X$: $\bc{\w} = \X^{-1}\y$. We take the multiplier “to the other side” just like we would do with a scalar equation. General rectangular matrices don’t have an inverse, but when we replace it by the pseudo-inverse, we get the least-squares solution, which will coincide with the ideal solution if one exists.
Note that if $\X$ has dimensions $n \times m$, then $\X^\dagger$ has dimensions $m \times n$. This is consistent with the idea that if $\X$ represents a function from $\mR^m$ to $\mR^n$, then something analogous to its inverse should represent a function from $\mR^n$ to $\mR^m$
What happens if $\X^T\X$ is not invertible? It turns out this this happens precisely when the rank of $\X$ is strictly less than the number of columns. One such case is if $\X$ is wider than it is tall, like the dataset of portrait images we saw in part one. This makes sense if you think back to the ideal solution to our problem: $\X\bc{\w} = \y$. If $\X$ is wider than it is tall (and full-rank) then this is a system of $n$ equations with $m$ variables: we will get many different solutions.
We can prove this fact simply from the SVD. This is a good illustration of how the SVD can be used for theoretical purposes. What we want to show is that if $\X^T\X$ is non-invertible, $\X$ must have a column rank less than $m$. Let $k < m$ be the rank of $\X$ and let
\[\X = \rc{\U}_m\gc{\Sig}_m{\rc{\V}_m}^T\]be the SVD of $\X$ truncated at $m$. Note that we only have $k$ singular values so some of the diagonal of $\gc{\Sig}_m$ is zero. Note also that the columns of $\rc{\V}_m$ have length $m$, so $\rc{\V}_m$ is square.
With this decomposition, we can write
$$\begin{align*} \X^T\X &= \rc{\V}_m{\gc{\Sig}_m}^T{\rc{\U}_m}^T\rc{\U}_m\gc{\Sig}_m{\rc{\V}_m}^T \\ &= \rc{\V}_m{\gc{\Sig}_m}^2{\rc{\V}_m}^T \end{align*}$$
where the $\rc{\U}_m$'s in the middle disappear, because $\rc{\U}_m$'s columns are orthogonal to one another, so together they form an identity matrix. Note also that $\gc{\Sig}_m$ is diagonal, so it's equal to its transpose and multiplying it by itself boils down to squaring the diagonal values.
The resulting decomposition is equal to the eigendecomposition of $\X^T\X$, which we already knew existed. However, what we’ve now shown as well, is that because $\X$ has lower rank than $m$, some of its eigenvalues are zero. We know that $\rc{\V}_m$ and ${\rc{\V}_m}^T$ are orthogonal, so they are invertible.
The composition of invertible matrices is invertible, so whether $\X^T\X$ is invertible boils down to whether ${\gc{\Sigma}_m}^2$ is invertible. A diagonal matrix with all nonzero values on the diagonal is invertible: when we multiply a vector by it, we multiply each element of the vector by one of the diagonal elements, so we can get back the original elements by multiplying by their inverses. However, the diagonal matrix with zeros on the diagonal is singular. We lose information if we multiply by it, because those elements of the input vector that were multiplied by zero cannot be recovered from the output vector.
That means that if $\X$ has rank $m$, ${\gc{\Sig}}^2$ has $m$ non-zero diagonal values, i.e. $\X^T\X$ must be invertible. If the rank of $\X$ is less than $m$, we get fewer nonzero values on the diagonal of ${\gc{\Sig}}^2$, and $\X^T\X$ is singular.
What should we do when $\X^T\X$ is singular? This means we have multiple exact solutions to our problem $\X\bc{\w} = \y$, so we need an additional constraint to choose a single one. One common heuristic in machine learning is to pick models for which the parameter values are small. The simplest option is to pick the $\bc{\w}$ that satisfies $\X\bc{\w} = \y$ for which $||\bc{\w}||$ is minimal.
One of the most beautiful properties of the pseudo-inverse is that if we define it carefully, it automatically delivers this solution if multiple solutions are available.
To show this, we will investigate what happens if we add a small invertible matrix to $\X^T\X$ to make it invertible. Specifically, we’ll add a small multiple $\oc{\epsilon}$ of the identity matrix. Doing this, the normal equation becomes
\[\left (\X^T\X + \oc{\epsilon}\I \right )\bc{\w} = \X^T\y \p\]The idea is that we can let $\oc{\epsilon}$ go to zero to see which solution the pseudo-inverse gives us.
To see why $\X^T\X + \oc{\epsilon}\I$ must be invertible, consider the vectors represented by its columns. If $\X^T\X$ is singular, and thus rank deficient, these must all lie in some subspace of lower dimension than $m$. By adding $\oc{\epsilon}\I$, we are pulling each vector a little bit in the direction of a different axis. Imagine two vectors on the same line. If I pull one a little toward the horizontal, and the other a little toward the vertical, they must leave the line they originally had in common.

We can now rewrite our modified normal equation as
\[\begin{align*} \X^T\X\bc{\w} = \X^T\y - \oc{\epsilon}\bc{\w} \p \end{align*}\]To get some insight into what the solutions to this equation look like, let’s imagine that we have an $n \times 2$ data matrix ($n$ instances, $2$ features) and that the first column of $\X$ happens to be a unit vector, and the second column is twice the first column. This gives us
\[\X^T\X = \begin{pmatrix}1 & 2 \\ 2 & 4 \end{pmatrix}\p\]This is a singular matrix: the second column is twice the first. Its operation is to squeeze the whole plane into a single line. Any $\bc{\w}$ is mapped to a point $(\rc{x}, 2\rc{x})$, with $\rc{x} = \bc{w}_1 + 2\bc{w_2}$.

The line of all points mapped to $(\rc{x}, 2\rc{x})$, its pre-image, is orthogonal to the line that forms the column space. In this specific instance, we can rewrite $\bc{w}_2 = -\frac{1}{2}\bc{w}_1 \kc{+ \frac{1}{2}x}$. That is, a line with slope $-\frac{1}{2}$, which we can tell by inspection is orthogonal to our line with slope $2$. But this is not just true in this istance, it holds more generally. For any matrix $\gc{\M}$, the pre-image of some point in $\text{col } \gc{\M}$ is orthogonal to the column space itself.
The original normal equation states that we want to choose $\bc{\w}$ so that $\X^T\X\bc{\w}$ coincides with the point $\X^T\y$. Since the second column of $\X$ is twice the first, we have
\[\X^T\y = \begin{pmatrix}y' \\ 2 y'\end{pmatrix}\]for some $y'$. This is on the line that corresponds to $\text{col } \X^T\X$. Every $\bc{\w}$ for which $\bc{w}_1 + 2\bc{\w}_2 = y'$, will be mapped onto this point giving us a solution for $\X^T\X\bc{\w} = \X^\y$

Now, when we introduce the term $\oc{\epsilon}\bc{\w}$ to the left-hand-side. This moves our target by a small multiple of $\bc{\w}$. Where formerly we got from $\bc{\w}$ to the target $\X^T\y$ in a single matrix multiplication, we now need two steps: first we multiply $\X^T\X\bc{\w}$ and then we add $\oc{\epsilon}\bc{\w}$. The first step is guaranteed to put us in the column space of $\X^T\X$, which is where the target is as well. Therefore, if we are going to reach the target, the second step should keep us in the column space. In other words, $\bc{\w}$ needs to point along the column space.

This is how the term $\oc{\epsilon}\bc{\w}$ moves us from a problem with multiple solutions a problem with a single solution. We’ve also claimed that this solution is the one with the smallest norm. How do we see this in the image? The trick is to note that the the line $\oc{P}$ from which we choose $\bc{\w}$ is orthogonal to the column space, which crosses the origin. This means that if we choose the point where the two cross, we are essentially projecting the origin onto $\oc{P}$. This means we’ve chosen the point on $\oc{P}$ that is closest to the origin, or, in other words, the solution with the smallest norm.
We’ve ignored the fact that we changed the target by the term $\oc{\epsilon}\I$, so we’ve slightly changed the model. But we can justify that by making $\oc{\epsilon}$ very small. The whole derivation still holds, so long as it’s non-zero. More technically, as we let $\oc{\epsilon}$ go to zero, our solution converges to the one with the lowest L2 norm.
This is a very neat principle, which we’d like to work into our definition of the pseudo-inverse. To this end, we can define $\X^\dagger$ as the matrix
\[\X^\dagger = \underset{\oc{\epsilon} \to 0}{\text{lim}}\;\;\left(\X^T\X + \oc{\epsilon}\I \right)^{-1}\X^T \p\]That is, if the inverse of $\X^T\X$ exists, we simply use it as before, but if it doesn’t, we instead use the matrix that is the limit of $\X^T\X + \oc{\epsilon}\I$ for ever smaller $\oc{\epsilon}$. In the context of our least squares problem, the limit adds an extra constraint so that we converge to the approximation to the inverse that will give us the solution with the smallest norm.
That was a long story, so let’s recap:
- The pseudo-inverse lets us solve matrix equations. Whenever you feel like moving a matrix to the other side by taking its inverse, but the inverse doesn’t exist, you can use the pseudo-inverse instead.
- This will give you an exact solution if one exists, and a least squares solution if it doesn’t.
- If multiple solutions exist, you’ll get the one with the smallest norm.
So, all in all, the pseudo-inverse is a pretty powerful tool. How do we compute it? Obviously, if we know that $\X$ has full column rank, we can just compute $\X^T\X$, take its inverse, and multiply by $\X^T$. But that isn’t always the nicest approach. For one thing, computing the inverse is a numerically unstable business. In fact you usually avoid it by computing the pseudo-inverse instead, even if the inverse exists. Another problem is that this only works for $\X$ with full column rank. Ideally, we would have a single simple algorithm that returns the limit version of the pseudo-inverse if $\X^T\X$ isn’t invertible, without us having to check.
As you may have guessed, one of the best ways of achieving this is by the singular value decomposition.
The algorithm is simple, so let’s start there, and show why it’s correct later. Given $\X$, we first compute its SVD
\[\X = \rc{\U}\gc{\Sig}\rc{\V}^T \p\]On the diagonal of $\gc{\Sig}$, replace all non-zero values $\gc{\sigma}$ by their inverse $\frac{1}{\gc{\sigma}}$, and call the resulting matrix $\gc{\Sig}^\dagger$. We then reverse the basis transformations, and the result is the pseudo-inverse:
\[\X^\dagger = \rc{\V}\gc{\Sig}^\dagger\rc{\U}^T \p\]If we don’t want to compute the full SVD, we get the same result with the truncated SVD, so long as we include all singular values.
The main reason that the SVD is the preferred way of computing the pseudo-inverse is one we’ve seen before: noise. In fact noise can be particularly disastrous when we compute the pseudo-inverse. A small amount of noise turns zero singular values into very small non-zero singular values. If we leave these untouched, we can see above that they become very big singular values in the pseudo-inverse because we take their inverse, when actually they should be ignored. In short, a small amount of noise in $\X$ creates a huge error in $\X^\dagger$. The SVD makes this process explicit, and allows us to simply treat very small singular values as zero, eliminating the problem.
Now, why does this algorithm give us the pseudo-inverse? Let’s first look at the case where $\X$ has full column rank $m$. In that case, the pseudo-inverse is simply:
\[\X^\dagger = \left( \X^T\X\right)^{-1}\X^T\]Replacing each $\X$ by its SVD, truncated to $m$ and omitting the subscripts to simplify the notation, we get
\[\begin{align*} \X^\dagger &= \left( \rc{\V}\gc{\Sig}\rc{\U}^T \rc{\U}\gc{\Sig}\rc{\V}^T \right)^{-1} \rc{\V}\gc{\Sig}\rc{\U}^T \\ &= \left( \rc{\V}\gc{\Sig}^2\rc{\V}^T \right)^{-1} \rc{\V}\gc{\Sig}\rc{\U}^T\\ &= \rc{\V}\gc{\Sig}^{-2}\rc{\V}^T \rc{\V}\gc{\Sig}\rc{\U}^T\\ &= \rc{\V}\gc{\Sig}^{-1}\rc{\U}^T \p \end{align*}\]Which is the result of the algorithm described above. Note that because we truncated at $m$, $\gc{\Sig}$ and $\rc{\V}$ are $ m \times m$.
To make it intuitive exactly how SVD is solving our problem here, we can return to an idea we used before when we were developing eigenvectors: everything is a lot easier when your matrices are diagonal. Let’s try that here. Imagine that $\X$ is a diagonal $n \times n$ matrix and we are looking for the vector $\bc{\w}$ that minimizes the distance between $\X\bc{\w}$ and a given $\y \in \mR^n$.

What we see here is that for a diagonal matrix, the choices for each $\bc{w}_i$ become in a sense independent. The only requirement for $\bc{w}_1$ is that it makes $X_{11}\bc{w}_1$ as close as possible to $y_1$. We can make them equal by setting $\bc{w}_1 = y_1 / X_{11}$, without worrying about the other parts of $\X$ or $\bc{\w}$. We can do the same thing for every $\bc{w}_{i}$.
If $\X$ is not square, but it is still diagonal, we get some extra zero rows or extra zero columns. In the first case, we can’t control the elements of $\X\bc{\w}$ corresponding to the zero rows, so we may not be able to produce $\y$ exactly. The best solution is to optimize for the values we can control. In short, the solution in the previous paragraph will give us the orthogonal projection onto the column space of $\X$. In the second case, when $\X$ is wide, we get some extra elements of $\bc{\w}$, which we can set to whatever we like, because they correspond to zero columns. Setting these to zero will give us the minimal-norm solution.

The important thing, in both cases, is that we can work out the optimal solution simply by solving the scalar equation $X_{ii}\bc{w}_i = y_i$ for every $\bc{w}_i$ individually.
When we studied eigenvectors, after we saw how easy things were for a diagonal matrix, all we needed to do to deal with non-diagonal matrices was to develop a diagonalization: a way to transform space to a basis where the transformation expressed by our matrix becomes expressed by a diagonal matrix.
That was the eigendecomposition. The singular value decomposition does the same thing for us here. It takes any non-diagonal matrix, and it gives us two orthogonal basis transformations $\rc{\U}$ and $\rc{\V}$, one for the input space and one for the output space so that the remainder of the transformation can be expressed as a (rectangular) diagonal matrix.
We can see this happen more clearly if we rewrite directly from the minimization objective. Note first that if we take the full SVD and move the basis transformation to the other side, we get \(\rc{\U}^T\X\rc{\V} = \gc{\Sig}\): with two changes of basis, $\X$ becomes a diagonal matrix. This suggests that if we rewrite the data $\X$ and the target values $\y$ in the right bases, the minimization becomes a simple diagonal objective. We can work out the correct transformations with some simple rewriting:
$$\begin{align} \|\X\bc{\w} - \y\| &= \|\rc{\U}\gc{\Sig}\rc{\V}^T\bc{\w} - \rc{\U}\rc{\U}^T\y \| \\ &= \|\gc{\Sig}\rc{\V}^T\bc{\w} - \rc{\U}^T\y \| \\ &= \|\gc{\Sig}\bc{\w}' - \y' \| \end{align}$$
with $\bc{\w}’ = \rc{\V}^T\bc{\w}$ and $\y’ = \rc{\U}^T\y$.
And with that, we have a diagonal minimization objective. If we compute the SVD of $\X$, we can transform $\y$ to $\y’$ easily. Once we find a solution for $\bc{\w}’$, we can easily transform it back to the desired $\bc{\w}$ by reversing the basis transformation: $\bc{\w} = \rc{\V}\bc{\w}’$.
For the solution to $\bc{\w}’$, there are a few different possible situations.
For now, let's stick with the assumption that $\X$ is full-rank. In that case, $\gc{\Sig}$ has non-zero elements all along its diagonal. We simply set $\bc{w}_i'$ equal to $y_i \gc{\Sigma}_{ii}$ and we exactly solve our problem. If $\gc{\Sig}$ is taller than it is wide, we have some left-over values of $\bc{\w}'$ with no corresponding elements of $\gc{\Sig}$. We can set these to whatever we like, so if we want the $\bc{\w}'$ with the smallest norm, we should set them to $0$.
Now, what do we do if $\X$ is rank deficient? If we follow the simple definition of the pseudoinverse, and fill in the SVD, we get stuck at:
\[\X^\dagger \overset{?}{=} \left( \rc{\V}\gc{\Sig}^2\rc{\V}^T \right)^{-1} \rc{\V}\gc{\Sig}\rc{\U}^T \p\]Only the first $k$ diagonal values of $\gc{\Sig}^2$ are nonzero, so $\rc{\V}\gc{\Sig}^2\rc{\V}^T$ does not have an inverse. The limit definition tells us to instead take the inverse of $\rc{\V}\gc{\Sig}^2\rc{\V}^T + \oc{\epsilon}\I$, and to let $\oc{\epsilon}$ go to zero. Why does this lead to the algorithm we described earlier? To me, it’s not immediately clear that adding these $\oc{\epsilon}$s will result in us ignoring the zeros on the diagonal of $\gc{\Sig}$, which is what the algorithm tells us to do.
Luckily, it’s easier to see in the minimization objective. We start with the modified normal equation
\[(\X^T\X + \oc{\epsilon}\I)\bc{\w} = \X^T\y\p\]Since $\X$ is rank deficient, this doesn’t have an exact solution. Instead, we can minimize the norm of the difference between the left and right sides. With a little rewriting, we get:
\[\begin{align*} \| (\X^T\X + \oc{\epsilon}\I)\bc{\w} - \X^T\y \| &= \| (\rc{\V}\gc{\Sig}^T\rc{\U}^T\rc{\U}\gc{\Sig}\rc{\V}^T + \oc{\epsilon}\rc{\V}\rc{\V}^T)\bc{\w} - \rc{\V}\gc{\Sig}^T\rc{\U}^T\y \| \\ &= \| (\gc{\Sig}^T\gc{\Sig}\rc{\V}^T + \oc{\epsilon}\rc{\V}^T)\bc{\w} - \gc{\Sig}^T\rc{\U}^T\y \| \\ &= \| (\gc{\Sig}^T\gc{\Sig} + \oc{\epsilon}\I)\rc{\V}^T\bc{\w} - \gc{\Sig}^T\rc{\U}^T\y \|^2 \\ &= \| (\gc{\Sig}^2 + \oc{\epsilon}\I)\bc{\w'} - \y' \| \end{align*}\]where we’ve set $\y’ = \gc{\Sig}^T\rc{\U}^T\y$ and $\bc{\w}’ = \rc{\V}^T\bc{\w}$. It’s a bit more complex than what we had before, but the principle is the same.
In the final line, we see that we again have a simple linear problem with a diagonal matrix: $\gc{\Sig}^2 + \oc{\epsilon}\I$. The solution to this problem is to solve, for each $\bc{w'}_i$, the scalar equation $({\gc{\Sigma}_{ii}}^2 + \oc{\epsilon}) \bc{w'}_i = {y'}_i$, which gives us $$\bc{w'}_i = \frac{ {y'}_i }{ {\gc{\Sigma}_{ii}}^2 + \oc{\epsilon} } \p$$ From the definition of $\y'$, we see that $y'_i = \gc{\Sigma}_{ii} \rc{\u}_{i} \cdot \y$ where $\rc{\u}_{i}$ is the $i$-th column of $\rc{\U}$. Filling this in, we get
$$ \bc{w'}_i = \frac{\gc{\Sigma}_{ii} \kc{\times {\u_i} ^T\y}}{{\gc{\Sigma}_{ii}}^2 + \oc{\epsilon}} \p $$
Here, we can see clearly where the problem of invertibility occurs: if $\gc{\Sigma}_{ii}$ is zero, and we don't add $\oc{\epsilon}$, we get a division by zero, which is undefined. The small $\oc{\epsilon}$ added to the diagonal of $\X^T\X$ ends up being added to the denominator, so we are preventing this division by zero.
The addition of $\oc{\epsilon}$ also affects the result for $\bc{w'}_i$ where $\gc{\Sig}_{ii}$ is nonzero, but we eliminate this effect by letting $\oc{\epsilon}$ go to zero. In that case, the solution goes to $\bc{w}_i = {\gc{\Sigma}_{ii}}^{-1} {\rc{\u}_i} ^T\y$
Putting all this together, we can derive the algorithm we already know. Given $\X$, we compute its SVD $\rc{\U}\gc{\Sig}\rc{\V}^T$. We transform our targets $\y$ to a new basis $\y’ = \gc{\Sig}^T\rc{\U}^T\y$. We solve the diagonal problem
\[\argmin{\bc{\w'}}\;\left \| \left( \gc{\Sig}^2 + \oc{\epsilon}\I \right)\bc{\w'} - \y'\right\|\]which we’ve shown above gives us
$$\bc{w}'_i = {\gc{\Sigma}_{ii}}^{-1} y_i' = {\gc{\Sigma}_{ii}}^{-1} {\rc{\u}_i}^T\y $$
if $\gc{\Sigma}_{ii} \neq 0$ and $\bc{w}'_i = 0$ otherwise. In matrix notation, we can write
\[\bc{\w'} = \gc{\Sig}^\dagger\rc{\U}^T\y \p\]Finally, we translate $\bc{\w’}$ back to $\bc{\w}$ by multiplying by $\bc{\V}$:
\[\bc{\w} = \rc{\V}\bc{\w'} = \rc{\V}\gc{\Sig}^\dagger\rc{\U}^T\y = \X^\dagger\y\]which is the algorithm we started out with.
As always, there are other ways of computing the pseudo-inverse, but we like the SVD method, because we can very cleanly eliminate any noise by simply taking the singular values that are close to zero and treating them as zero.
So, what have we learned? Firstly, that the least squares linear regression problem is solved by forming the pseudo-inverse, and secondly, that the pseudo-inverse can be computed very robustly by taking the SVD, inverting the nonzero values of $\gc{\Sig}$, multiplying it back together and transposing it.
But don’t think that all this is good for is linear regression. What we’ve shown here is the basis behind pretty much any linear learning method. Imagine that you have a large space of points $\mR^n$ and some target $\y$ anywhere in that space. You are looking for a point $\x \in \mR^n$ as close to $\y$ as possible but under the constraint that $\x$ is in some linear subspace $\rc{P}$ of dimension $n$. In that case the pseudo-inverse will give you your solution, quickly and precisely. This may sound a bit abstract, but it covers a huge swathe of search problems in machine learning, optimization and computer vision.
Even if your problem isn’t linear, for instance if you’re training a neural network, this can be a worthwhile perspective. Such models are usually trained by assuming that they are locally linear, computing the linear solution to this local approximation, and then taking a small step towards this solution. This is, for instance, how gradient descent operates. Even if you are training a non-linear model, the linear perspective can tell you a lot.
Finally, it’s worth taking a minute to consider what all this boils down to. The best approximation theorem at heart is nothing more than an application of the Pythagorean theorem. When I first learned that theorem, long ago, I didn’t really get what the big deal was, why this theorem was so much more famous than any other one in Euclidean geometry. Now, I see that pretty much everything we do in statistics and machine learning comes down to the best approximation theorem, which in turn is built on the Pythagorean theorem.
Making use of the SVD
To finish up, let’s see what else the pseudo-inverse and SVD can do for us. I promised that the basic framework of the best approximation theorem popped up in a lot of places, so let’s make good on that promise with a few examples. The last example will, once again, bring us back to principal component analysis.
Compression and noise removal
Let’s start by looking a little closer at something we’ve glossed over in the story so far: the idea of noise. We’ve said that one of the main benefits of the SVD is that it easily allows us to remove noise. If we have a low-rank matrix that contains some data that we’re interested in, but through some process like measurement error or floating point computation, a little noise has been added, we saw that the singular values that were zero before will now be small non-zero values. Setting these back to zero removes a large part of the noise.
The idea of noise is an important and very deep subject in machine learning and statistics. If you look up an official definition of noise in data analysis, you may find some assertion that the noise is the “random part” of the data. The pattern is caused by a mechanism, and the noise is a random signal “without cause” that is added on top. The pattern and the noise together make the data we observe.
This is an interesting perspective, but in practice it doesn’t quite work like that. What constitutes noise is usually a very subjective choice. Two people may look at the same data, and consider different parts noise. To explain, imagine that you’ve decided to weigh yourself regularly and to analyse the resulting data.
If you’re looking to lose weight, you’re probably only interested in a rough weekly trend. The daily fluctuations won’t mean much, but over a whole week, you can tell whether your current diet and exercise regime is working. In this view, the first-ordertrend is all you’re interested in. The rest you can treat as random noise. It’s not random in the sense that there is no cause behind it, it’s just that we are interested in looking at the data at a more granular level.
If you are interested in something else, you may want to retain more of the data. For instance, you might wonder whether it’s true that eating starchy food causes you to retain water, increasing your weight the next day. In that case, you are interested in the difference between successive days, based on what you ate the day before. You may even be interested in the way in which your metabolism changes throughout the day, in which case, you’d want to retain all the fine detail of the data over the course of the day (assuming you weigh yourself often enough).
In short, what you consider noise and what you consider pattern is a subjective choice, depending on what you do want to do with the data.
In some sense this is true of almost anything we call random. In theory, we could predict quite accurately how a flipped coin will land if we had a good idea of the state of the atmosphere around the coin, and the amount of force impacting the coin at the start of the flip. In practice, we usually treat all of this as unknown: we call it noise or randomness, and we say that the coin will land either side with equal probability. It’s not random because there’s no cause and effect, it’s random because we don’t care about that part of the process.
All this is just to make the point that what we filter out as noise is mostly determined by how we want to model the world. If we’re interested in losing weight, we will treat the data as roughly linear (on the scale of a week), and ignore any finer detail. We will treat this as random noise when we fit a line through our data, not because it’s truly random, but because the causes are too complex to model, and because they are irrelevant to our goal.
The relevance to SVD is that when we set the noise threshold in SVD, we are implicitly making this choice. So far we’ve said that there will be an obvious difference between the true singular vectors and those caused by noise, and often this is true, but it would be more accurate to say that we are choosing which parts to treat as noise.
If we wanted to, we could ramp up the threshold, and also zero out some of the more substantial singular vectors. The ones that were definitely not introduced by simple measurement error or floating point computations. This is essentially what happens when we compute a truncated SVD. We can either choose the number of singular vectors to retain, or set the noise threshold.
We’ve seen an example of this already, although we didn’t know it at the time. In part one, we reconstructed our face data step by step, by adding more principal components. The principal component are the singular vectors, so this process is equivalent to taking an SVD decomposition, truncated at $k$, and looking at the reconstructed data.

We see that at the high end, we get singular values with a magnitude between $0.1$ and $1.0$. This corresponds to things like camera noise, compression artifacts and floating point errors in the computation of the SVD itself. Reconstructing the data from only the principal components with singular values above this noise level results in a barely noticeable smoothing of the images but little loss in identifiability.
If we set the noise threshold higher, around $10$, we begin to lose some of the detailed facial features but the basic identity of each person is still retained. If we go even higher than that, to around $100$, only a handful of principal components remain. We see that the faces are so smoothed out that only basic properties like gender, age and lighting direction are retained.
Compressing single images
Representing images with their principal components in a larger dataset is a kind of image compression “in context”. We can work out that age and gender are important attributes because they are important causes of variation in the images in the set. In practice, image compression happens on one image at a time, without explicit reference to a larger set of images they belong too.
In this setting, we can also apply the SVD. Instead of flattening the image into a vector, we keep the image as a grid of pixels, and treat that grid as out matrix $\gc{\M}$. We’ll assume we have a grayscale image with pixel values encoded as numbers between $0$ (for black) and $1$ (for white). What can we expect to happen if we apply an SVD to this matrix?
\[\gc{\M} = \rc{\U}\gc{\Sig}\rc{\V}^T\]The first thing to note is that we get a perfect reconstruction (at least in theory) if we compute a full SVD. But then the three matrices $\rc{\U}$, $\gc{\Sig}$, $\rc{\V}$ contain many more values than the matrix $\gc{\M}$, so we’re not exactly achieving compression.
What happens if we use a compact SVD? That way we still have all the information, but we don’t use as many numbers to represent $\gc{\M}$ as the full SVD does. In his case, it depends on the image. For some images, the whole thing may be described with only a handful of singular vectors and values. In that case, the compact SVD will be much more efficient. This happens if the image itself is a low-rank matrix.
In most cases, if we want compression, we’ll need to use a truncated SVD. That is we will throw away information, but we will hopefully end up with an image that still looks to us like the original.
As we illustrate what this looks like, we can also show a link to the rank decomposition, we introduced earlier. This is a decomposition of the $n \times m$ matrix $\gc{\M}$ into the product $\bc{\A}\rc{\B}$ of an $n \times k$ matrix $\bc{\A}$ and a $k \times m$ matrix $\rc{\B}$

There are plenty of interesting patterns in the above photograph, but we can also tell immediately that the matrix $\gc{\M}$ is either low-rank or very close to it. On the left there are several columns of pixels that are almost entirely white, save for a gentle gradient into light gray. If just one of these columns is an exact scalar multiple of another, or a linear combination of several others, the matrix is rank deficient. More generally, because these columns are all close to being the same, we can treat them as such to compress them.
Now, how do we find the rank decomposition? It may not surprise you to learn that the SVD can help us here.
If we can find two matrices such that they multiply to form something close to $\gc{\M}$, and we can keep $k$ small enough, we will have achieved compression. We can easily turn the truncated SVD into an approximate rank decomposition: the matrices $\rc{\U}_k$ and ${\rc{\V}_k}^T$ have the right dimensions already. All we need to do is add the singular values. The simplest thing to do is to take the squares of the first $k$ singular values, arrange the in a diagonal matrix $\gc{\Sig}^\frac{1}{2}$, so that $\gc{\Sig}^\frac{1}{2}\gc{\Sig}^\frac{1}{2} = \gc{\Sig}_k$ and write
\[\gc{\M} \approx \bc{\A}\rc{\B} = \rc{\U}_k\gc{\Sig}^\frac{1}{2}\gc{\Sig}^\frac{1}{2}\rc{\V}_k^T = \rc{\U}_k\gc{\Sig}_k\rc{\V}_k^T\]with $\bc{\A} = \rc{\U}\gc{\Sig}^\frac{1}{2}$ and $\rc{\B} = \gc{\Sig}^\frac{1}{2}\rc{\V}^T$.
This gives us a quick way to compute a decomposition of an image matrix. Here’s what this looks like at different levels of truncation.








Computing rank decompositions
How good is this as an approximation of $\gc{\M}$ using a rank decomposition? It turns out it’s optimal. The Eckart-Young-Mirsky theorem tells us that no two rank-$k$ matrices can multiply to produce a matrix that is closer than $\A\B$. There are others that are equally close, but none are better.
This sounds like another best-approximation theorem. The proof of this fact is pretty straightforward, but it doesn’t illustrate how this relates to the best approximation results we’ve seen already. To make that link clear, we’ll look at something a little short of a formal proof, which will hopefully provide more intuition into what is happening when we approximate a matrix this way.
First, let’s state the problem formally. We are looking for two matrices $\bc{\A}$ and $\rc{\B}$ with sizes $n \times k$ and $k \times m$ so that \(\| \bc{\A}\rc{\B} - \gc{\M} \|\) is as small as possible.
This is a bi-linear minimization objective. If we fix $\bc{\A}$, we can use what we already know about linear problems to find the optimal $\rc{\B}$ and vice versa. To illustrate, let’s first assume that the opimal $\bc{\A}$ is given and we only need to find $\rc{\B}$.
To apply what we’ve learned about the pseudo-inverse, we can proceed column by column. Looking at a matrix multiplication, we know that whatever $\rc{\B}$ we choose, the $i$-th column of $\rc{\B}$ multiplies by $\bc{\A}$ to make the $i$-th column of $\gc{\M}$: $\bc{\A}\rc{\b}_i = \gc{\m}_i$.

This is entirely independent of what we choose for the other columns: if we change something in $\rc{\b}_i$, only $\gc{\m}_i$ is affected. Thus, we can treat this as a separate optimization problem for each column, and apply the pseudo-inverse to each. The solution is
\[\rc{\b}_i = \bc{\A}^\dagger\gc{\m}_i \p\]If we combine the columns $\rc{\b}_i$ back into a matrix, we get
$$ \rc{\B} = \left[\,\rc{\b}_1\,\ldots \,\rc{\b}_m\,\right] = \left[\,\bc{\A}^\dagger\gc{\m}_1 \,\ldots\, \bc{\A}^\dagger\gc{\m}_m\,\right] = \bc{\A}^\dagger \gc{\M} \p $$
In short, solving $\bc{\A}\rc{\B} = \gc{\M}$ for $\rc{\B}$, we find that $\rc{\B} = \bc{\A}^\dagger\gc{\M}$. We take $\bc{\A}$ to the other side using the pseudo-inverse, analogous to the way we would solve a scalar equation.
If we reverse the setting, and assume that $\rc{\B}$ is given, we can take the transpose of all matrices so that our objective becomes $\| \rc{\B}^T\bc{\A}^T - \gc{\M}^T \|$. We can then follow the same derivation as above, finding that the rows of $\bc{\A}$ multiply by $\rc{\B}^T$ to make the rows of $\gc{\M}$. Ultimately, the optimal choice of $\bc{\A}$ becomes
\[\bc{\A} = \gc{\M}\rc{\B}^\dagger \p\]This gives us two equations that should hold at the optimum. We can now show that the SVD solution to the rank decomposition problem we described above satisfies these equations.
First, we take the SVD of $\gc{\M}$ truncated at $k$:
\[\gc{\M} \approx \rc{\U}\gc{\Sig}\rc{\V}^T \p\]We’ve ommitted the subscripts for clarity, but note that $\rc{\U}$ is $n \times k$, $\gc{\Sig}$ is $k \times k$ and $\rc{\V}$ is $m \times k$.
If we define $\bc{\A} = \rc{\U}\gc{\Sig}^\frac{1}{2}$ and $\rc{\B} = \gc{\Sig}^\frac{1}{2}\rc{\V}^T$ then they combine into a low rank approximation of $\gc{\M}$ as we already showed. What we can also conclude is that this gives us the SVD decompositions of $\bc{\A}$ and $\rc{\B}$. All we need is to add a $k \times k$ identity matrix:
$$\begin{align*} \bc{\A} &= \rc{\U}\gc{\Sig}^\frac{1}{2}\rc{\I}^\kc{T} \\ \rc{\B} &= \rc{\I}\gc{\Sig}^\frac{1}{2}\rc{\V}^T \p \end{align*}$$
This in turn, tells us what the pseudo-inverses of $\A$ and $\B$ are.
$$\begin{align*} \bc{\A}^\dagger &= \rc{\I}\gc{\Sig}^{-\frac{1}{2}}\rc{\U}^T \\ \rc{\B}^\dagger &= \rc{\V}\gc{\Sig}^{-\frac{1}{2}}\rc{\I}^\kc{T} \p \end{align*}$$
We can now simply fill in these definitions to show that the required equations hold for this choice of $\bc{\A}$ and $\rc{\B}$. For $\bc{\A}$ we get
$$\begin{align*} \bc{\A} &= \rc{\U}\gc{\Sig}^\frac{1}{2}\rc{\I}^\kc{T} \\ &= \rc{\U}\gc{\Sig}\gc{\Sig}^{-\frac{1}{2}}\rc{\I}^\kc{T}\\ &= \rc{\U}\gc{\Sig}\rc{\V}^T\rc{\V}\gc{\Sig}^{-\frac{1}{2}}\rc{\I}^\kc{T}\\ &= \gc{\M}\rc{\B}^\dagger \p \end{align*}$$
And for $\rc{\B}$
$$\begin{align*} \rc{\B} &= \rc{\I}\gc{\Sig}^\frac{1}{2}\rc{\V}^T \\ &= \rc{\I}\gc{\Sig}^{-\frac{1}{2}}\gc{\Sig}\rc{\V}^T \\ &= \rc{\I}\gc{\Sig}^{-\frac{1}{2}}\rc{\U}^T\rc{\U}\gc{\Sig}\rc{\V}^T \\ &= \bc{\A}^\dagger\gc{\M}\p \end{align*}$$
This isn’t a complete proof. We have only shown that one necessary condition holds. To complete the proof, we should show that this condition is also sufficient. This is possible, but a bit technical. Instead, we’ll wait until we tie this back into principal component analysis, in the next subsection. There, we will see that the results we already know will serve as a proof of the Eckart-Young-Mirsky theorem.
So, in summary, the SVD gives us a very efficient way to approximate matrices by compressed representations. We started with image compression as a use case, because it’s a visual example. But there are many other situations where our data forms a matrix, and in any such case, the rank decomposition, computed by SVD, provides us with an efficient mechanism to separate pattern from noise. Either for compression, analysis or for prediction.
Recommendation
One particularly relevant and popular example is that of recommendation. This is where we see that the SVD can be a powerful tool for prediction.
Imagine that you are running a movie streaming service. You have a large collection of movies and a large population of users.
Each user has given you a few ratings for a small subset of the movies. This rating consists of a high positive number if they like the movie, a high negative number if they dislike the movie and something near zero if they were ambivalent.
If we have $\oc{n}$ users, and $\bc{m}$ movies, we can put these ratings in a big $\oc{n} \times \bc{m}$ matrix $\R$. The element $R_{\oc{i}\bc{j}}$ tells us what user $\oc{i}$ thought of movie $\bc{j}$. For some pairs $\oc{i}, \bc{j}$, we don’t have a rating (if we knew the whole matrix, we wouldn’t need a recommender). For now, we’ll set these elements of the matrix to zero, and see what we can do.
Let’s see what happens if we apply a rank decomposition to the matrix $\R$. We’ll get one $\oc{n} \times k$ matrix $\oc{\U}$, and one $\bc{m} \times k$ matrix $\bc{\M}$ such that $\R \approx \oc{\U}\bc{\M}^T$.

We can think of the $\oc{i}$-th row of $\oc{\U}$ as a representation of the $\oc{i}$-th user and the $\bc{j}$-th row of $\bc{\M}$ as a representation of the $\bc{j}$-th movie. Their dot product is the approximation to the rating $R_{\oc{i}\bc{j}}$. The basic idea of this kind of recommendation is that if $R_{\oc{i}\bc{j}}$ approximates the known ratings well, then it may approximate the unknown ratings too. We can think of $R_{\oc{i}\bc{j}}$ as a prediction for whether user $\oc{i}$ will like movie $\bc{j}$.
What might a good solution to this problem look like? Here’s one way to think about it. Imagine that we were to fill in the user representation $\oc{\u}$ and the movie representation $\bc{\m}$ by hand, in such a way that their dot product would be positive if the user likes the movie and negative if the user dislikes the movie.
One way to do this is to come up with $k$ features a movie can have, like comedy, drama and romance. You can score the movie on each aspect, giving it for instance, a large negative score if for comedy if the movie is highly un-comedic and a zero for romance if the movie is neither romantic nor unromantic.
We can then score the user in a similar way based on how much they like these aspects. If the used loves comedy, we give them a large score for comedy. If they hate romance, we give them a large negative score for romance, and if they are ambivalent about drama, we give them a zero for drama.

If we have all this information for the user and the movie, then we can see that the dot product is a great predictor for how much the user will like the movie.
Note that if two aspects have the same sign: the user likes romance and the movie contains it, or the user hates romance and the movie is unromantic, both lead to a higher score. Similarly, if two aspects have opposite signs the score is lowered. Finally, note that if one aspect is near zero, that aspect does not affect the score. For instance, if the user is ambivalent about the amount of romance, it doesn’t matter for the score whether or not the movie contains a lot or romance or is totally unromantic.
In practice, we don’t have the means to collect all this information for our users and movies. Instead, we collect ratings, and we learn the representations for our users and movies by decomposing the rating matrix.
The surprising thing is that matrix decomposition still learns intepretable features. Here are the first two dimensions in this learned space from a simple matrix decomposition of a movie rating dataset.

This is an interesting takeaway of the recommender system use case: it shows us how we can interpret the rows of the two matrices we’ve decomposed $\R$ into. In general, if we decompose $\gc{\M}$ into $\bc{\A}\rc{\B}$, then the $i$-th row of $\bc{\A}$ is a vector representation of the element represented in the $i$-th row of $\gc{\M}$. In movie recommendation, this is the $i$-th user, and in image compression, it’s something more abstract like the $i$-th row of pixels. Likewise, the $j$-th column of $\rc{\B}$ is a learned representation of whatever the $j$-th column of $\gc{\M}$ represents.
The hyperparameter $k$ gives us a classic under/overfitting tradeoff. For low $k$, we have little space to model many aspects of our users and movies. We won’t fit much of the pattern in the data, but we can be sure that we are ignoring any noise. If $k$ gets higher, we can model the existing ratings more accurately, but at some point we will also be capturing more and more of the noise. At this point we are fitting the original ratings too accurately, and the representations may no longer generalize to user/movie pairs for which the rating is unknown.
One interesting aspect about the movie recommendation problem is that the matrix that we decompose is incomplete. As a first line of attack, we just set the missing values to $0$ and applied the matrix decomposition anyway. In practice, this tells the algorithm to optimize for a lot of values that we actually don’t want to optimize for. What we can do instead, is compute the minimization objective only for the known values.
It’s easy to see how this should be done if we open up the minimization objective a little. Focusing on the square of the norm, we see that
\[\| \R - \oc{\U}\bc{\M} \|^2 = \sum_{\oc{i},\bc{j}} \left(R_{\oc{i}\bc{j}} - \oc{\u_i}^T\bc{\m_j}\right)^2\p\]If we replace the sum on the right, over all elements $\oc{i}, \bc{j}$ by a sum over only the known elements of the matrix $\R$, we get an optimization objective that optimizes only for the known values. The downside is that in this case we can no longer solve the problem analytically (by computing an SVD). We need to use methods like gradient descent or alternating least squares to find a good solution.
But even if the traditional SVD doesn’t allow us to compute the optimal decomposition here, we can take inspiration from this use case, for how to define the SVD if our matrix $\gc{\M}$ is only partly known. Our original derivation of the SVD started with us multiplying unit vectors by $\gc{\M}$ and seeing which caused the largest resulting vector. This derivation doesn’t translate to the case where we don’t know some elements of $\gc{\M}$, but now have some another perspective to build on.
We can define the $k$-truncated SVD as the solution to the low-rank approximation problem. This problem we can solve with a partial matrix, so we can use it to define a partial SVD, even if we’ll need to solve with gradient descent.
We can define this more precisely, but, first, we’ll look at one more use case, which will tie everything together. It will give us a complete proof of the Eckhart-Young-Mirsky theorem, show us how to do SVD on partially known matrices, and most importantly, bring us back to familiar territory.
PCA as matrix decomposition
It’s only fitting that we end back where we started, at principal component analysis. Now that we have added matrix decompositions to our toolbelt, we can view PCA from this perspective.
Let’s start with a given PCA, using $k$ components. If we place the principal components of the data in an $n \times k$ matrix $\bc{\Z}$, with each row representing an instance, and the reconstruction vectors in an $m \times k$ matrix $\rc{\C}$, then we can illustrate the whole PCA analysis with single matrix multiplication.

Here we see that PCA is nothing but a low-rank approximation of our data matrix $\X$, albeit with the extra constraint that the columns of $\bc{\Z}$ and $\rc{\C}$ should be mutually orthogonal unit vectors.
One particularly useful aspect of this perspective is that it shows that we’ve already proved the Eckart-Young-Mirsky theorem.
In part two, we showed that PCA provides an optimal reconstruction from a lower dimensional representation, under the constraints that the reconstruction is linear and consists of orthogonal vectors.
First, note that the second constraint does not actually limit the quality of the solution. If we find a solution with non-orthogonal vectors, we can always convert them to an orthogonal set of vectors, keeping the reconstruction the same.
The conclusion is that if we have any matrix $\gc{\M}$ and ask for a rank $k$ approximation, we can interpret $\gc{\M}$ as a data matrix and apply PCA. This will give us two matrices $\bc{\Z}$ and $\rc{\C}$ which we have already shown in previous parts to be an optimal approximation to $\gc{\M}$. As we already derived earlier, if we have a full SVD $\gc{\M} = \rc{\U}\gc{\Sig}\rc{\V}^T$, then the PCA can be computed as $\bc{\Z} = \rc{\U}\gc{\Sig}$ and $\rc{\C} = \rc{\V}$.
So, Eckart-Young-Mirsky properly proved. However, we can do a little better. EYM doesn’t tell us that the SVD solution is the only optimal low-rank approximation to $\gc{\M}$. There is a large set of solutions. What makes the SVD an especially useful member of this set is that it satisfies some extra requirements.
We’ve been here before with the PCA solution. We characterized the PCA objective originally as a reconstruction objective, and we noted that there we many solutions, even if we constrained them to be orthogonal. The PCA soluton was special because even if we optimize for $k$ principal components, the PCA solution is the one for wich we can isolate the first $r$ principal components and get a PCA solution for the problem with $r$.
This is what makes the SVD unique among the solutions to the low rank approximation problem. A full SVD can be truncated at every $k$ to give a solution to the rank $k$ decomposition problem. A $k$-truncated SVD can be truncated at $r < k$, to give a solution to the rank $r$ problem.
What we can now do is take this as a definition of the SVD. Then we can generalize to a definition for SVD under missing values. The first singular value $\gc{\sigma}$, and its two singular vectors $\rc{\u}$, $\rc{\v}$, we choose in such a way that they minimize the reconstruction objective:
\[\|\gc{\M} - \rc{\u}\gc{\sigma}\rc{\v}^T\| = \sum_{i,j} \left(\gc{M}_{ij} - \left(\rc{\u}\gc{\sigma}\rc{\v}^T \right)_{ij}\right)^2\]subject to the constraint that $\rc{\u}$ and $\rc{\v}$ are unit vectors. If some values of $\gc{\M}$ are unknown, we sum only over the known values.
This is not how we defined first the singular vectors above. Instead, we looked for the unit vector that yielded the largest vector when multiplied by $\gc{\M}$. This definition doesn’t work with missing values, of course, because we can’t compute the matrix multiplication unless all values of $\gc{\M}$ are known. We know that the two definitions are equivalent, but only because we know that the SVD computes the PCA, and the first principal component can be defined this way.
If that feels like going the long way round, here is a more direct proof of the equivalence. We start with the reconstruction objective.
$$\begin{align*} \argmin{\rc{\u}\; \rc{\v}\; \gc{\sigma}}\;\;&\|\gc{\M} - \rc{\u}\gc{\sigma}\rc{\v}^T\|^2 \\ \text{such that}\;\;& \|\rc{\u}\| = \|\rc{\v}\| = 1 \p \\ \end{align*}$$
Opening up the norm in the objective, we get
$$\begin{align*} \|\gc{\M} - \rc{\u}\gc{\sigma}\rc{\v}^T\|^2 &= \sum_{ij} \left( \gc{M}_{ij} - \rc{u}_i\gc{\sigma}\rc{v}_j\right)^2\\ &= \sum_{i} \| \gc{\m}_i - \rc{u}_i\gc{\sigma}\rc{\v}\|^2 \end{align*}$$
where $\gc{\m}_i$ is the $i$-th row of $\gc{\M}$. If $\gc{\M}$ is a data matrix, you can think of this as breaking up the reconstruction error over the whole matrix into a sum over the reconstruction error per instance.
Now, we apply the central trick that we first saw in part 2: that reconstruction error is related to variance by the Pythagorean theorem (it always comes back to Pythagoras).
Looking at the following diagram

we see that we have
\[\|\gc{\m}_i\|^2 = \|\gc{\m}_i - \rc{u}_i\gc{\sigma}\rc{\v}\|^2 + \|\rc{u}_i\gc{\sigma}\rc{\v}\|^2\]or, over all $i$
\[\sum_i \|\gc{\m}_i\|^2 = \sum_i\|\gc{\m}_i - \rc{u}_i\gc{\sigma}\rc{\v}\|^2 + \sum_i \|\rc{u}_i\gc{\sigma}\rc{\v}\|^2\]The left hand side is a constant, so minimizing one term on the right is equivalent to maximizing the other. With that, our objective becomes
$$\begin{align*} \argmax{\rc{\v}\; \rc{\u}\; \gc{\sigma}} & \sum_i \|\rc{u}_i\gc{\sigma}\rc{\v}\|^2 \\ \text{such that}\;\;& \|\rc{\u}\| = \|\rc{\v}\| = 1 \\ \end{align*}$$
Now, note that $\rc{\v} = 1$, so that $|\rc{u}_i\gc{\sigma}\rc{\v}|^2 = {\rc{u}_i}^2\gc{\sigma}^2$. This turns the objective into $\sum_i {\rc{u}_i}^2\gc{\sigma}^2 = \gc{\sigma}^2\sum_i\rc{\u}_i = \gc{\sigma}^2|\rc{\u}|$, so that we get
$$\begin{align*} \argmax{\rc{\v}\; \rc{\u}\; \gc{\sigma}}\;\;& \gc{\sigma}^2 \\ \text{such that}\;\;& \|\rc{\u}\| = \|\rc{\v}\| = 1 \\ \text{and}\;\;& \|\gc{\M}\rc{\v}\| = \gc{\sigma}\rc{\u} \end{align*}$$
or, equivalently
$$\begin{align*} \argmax{\rc{\v}}\;\;& \gc{\M}\rc{\v} \\ \text{such that}\;\;& \|\rc{\v}\| = 1 \p \\ \end{align*}$$
So, the reconstruction definition is equivalent to the “maximum stretch” definition for the first singular vector. The definition is the same for the other singular vectors, with the exception that there are additional constraints, so the same proof will work for the other singular vectors too.
We can now define an SVD for matrices that are only partially known, for instance, a recommendation matrix, or a data matrix with missing values. We simply use the reconstruction definition, and compute the reconstruction only over the known values.
The downside of this approach is that the problem is no longer easy to solve. The fast and robust algorithms that we have to compute SVDs for complete matrices don’t work for incomplete ones. Instead we need to look to iterative approaches. There are a few options, but simple gradient descent is the simplest and probably the most popular. If we want a proper SVD, with the singular vectors separated and arranged by magnitude, we’ll need to work them out iteratively. We search for the first singular vector, and once we’ve found it we search for the second singular vector orthogonal to it. This is like the iterative algorithm for PCA we introduced in part 1. It’s slow, but we get a proper SVD with separated singular values.
If we don’t want to wait that long, we can also solve the reconstruction problem in one go: find two orthogonal matrices $\rc{\U}$ and $\rc{\V}$ and a diagonal matrix $\gc{\Sig}$ so that their product approximates our matrix, all truncated to $k$ dimensions. The downside, like the combined approach to solving the PCA problem, is that we don’t get a neat separation of the singular vectors. If we truncate at $k$, we can find a solution that is as good as the iterative solution, but the $k$ vectors we find will be a mixture of the $k$ vectors that the iterative algorithm returns.
Conclusion
So that’s the singular value decomposition. The workhorse of linear algebra.
In the context of PCA, you can think of the SVD as a way to compute a principal component analysis efficiently, but you can also think of it as an alternative definition. In part one, we defined the PCA in term of minimizing reconstruction error, in part two, we defined it in terms of the eigenvectors of the covariance matrix, and here we have defined it a third time, in terms of the singular values of the data matrix. All of these definitions are, of course, equivalent, and all of them have different things to offer.
The main thing the SVD definition has to offer is that it is the preferred way to compute a principal component analysis. If you’re willing to take an SVD routine as a given, you now have everything you need to compute the PCA in almost all settings. And in almost all cases, that is what you should do. There are very few situations where you would want to implement your own SVD algorithm.
Still, can we really claim to have understood SVD, and by extension PCA, if we cannot implement it from scratch? In the next part we will take the final step in our journey, and look at some algorithms for computing both eigenvectors and singular vectors.
Acknowledgements Many thanks to Charlie Lu for corrections.
Appendix
Proofs
Let $\gc{\M}$ be any matrix with $k$ singular values and let $\gc{\M} = \rc{\U}\gc{\Sig}\rc{\V}^T$ be its full SVD. Then, the compact SVD $\gc{\M} = \rc{\U}_k\gc{\Sig}_k{\rc{\V}_k}^T$ also holds.
Proof. We denote the different submatrices of the full SVD as follows.

We can now prove what we want—that $\rc{\U}'$, $\rc{\V}'$, and the zeroes around $\gc{\Sig}_k$ aren't necessary to decompose $\gc{\M}$—simply by a small number of rewriting steps. To do this, it's useful to know how matrix multiplication distributes over this concatenation operator $\left [\;\right ]$. It depends on whether the "split" in the matrix is parallel to the dimension we match to multiply or orthogonal to it.
If the split is parallel, as in the multiplication $\left [ \begin{array}~\A\\ \B \end{array}\right] \C$, the result is another concatenated matrix, but with each submatrix multiplied by $\C$:
$$\left [ \begin{array}~\A\\ \B \end{array}\right] \C = \left [ \begin{array}~\A\C\\ \B\C \end{array}\right] $$
If the split is orthogonal, as in the multiplication $\left [\A \;\B \right]\,\C$, we must split the other matrix $\C$ into submatrices $\C_1$, $\C_2$ to match, and the result is the sum:
$$\left [\,\A \;\B \,\right]\,\C = \A\C_1 + \B\C_2 \p$$
With these two rules, we can take the full SVD, and simply distribute the matrix multiplications out over the various concatenations.
$$\begin{align*} \gc{\M} &= \rc{\U}\gc{\Sig}\rc{\V}^T \\ &= \left [ \rc{\U}_k \; \rc{\U}'\right ] \left [ \begin{array} ~\gc{\Sigma}_k & \kc{\mathbf 0} \\ \kc{\mathbf 0} & \kc{\mathbf 0} \\ \end{array}\right ] \rc{\V}^T\\ &= \rc{\U}_k \left [ \begin{array} ~\gc{\Sigma}_k & \kc{\mathbf 0} \\ \end{array}\right ] \rc{\V}^T + \kc{\U'\left [ \begin{array} ~ \mathbf 0 & \mathbf 0 \\ \end{array}\right ] \V^T}\\ &= \rc{\U}_k \left [ \begin{array} ~\gc{\Sigma}_k & \kc{\mathbf 0} \end{array}\right ] \left [\rc{\V}_k^T \;\rc{\V}'^T\right]\\ &= \rc{\U}_k \gc{\Sigma}_k \rc{\V}_k^T + \kc{\U_k{\mathbf 0} \V'^T} \\ &= \rc{\U}_k \gc{\Sigma}_k \rc{\V}_k^T \end{align*}$$
The pre-image of a point in a column space is orthogonal to the column space.
Proof. Let $\gc{\M}\x = \gc{\M}\y$, let $\z \in \text{\col }\gc{\M}$ and let $\gc{\M} = \left[\,\gc{\m}_1 \ldots \gc{\m}_m\,\right]$. Then, for some $z'_1 \ldots z'_m$ we can write $\z = z'_1\gc{\m}_1 + \ldots + \z'_m\gc{\m}_m$. Thus,
$$ \begin{align} \z^T(\x - \y) &= (z'_1\gc{\m}_1 + \ldots + \z'_m\gc{\m}_m)^T(\x - \y) \\ &= (z'_1\gc{\m}_1x_1 + \ldots + \z'_m\gc{\m}_mx_m) - (z'_1\gc{\m}_1y_1 + \ldots + \z'_m\gc{\m}_my_m) \\ &= \z'\gc{\M}\x - \z'\gc{M}\y = 0 \p \end{align} $$This tells us that the difference between any two vectors in the pre-image of a point is orthogonal to any vector in the column space of $\gc{\M}$, so the two are orthogonal.